✍️ 기본 미션
p. 125의 확인 문제 2번, p. 155의 확인 문제 4번 풀고 인증하기.
P. 125 확인문제 2
Q. 설명에 맞는 레지스터를 찾아 빈칸을 채워 보시오.
A.
[ 플래그 레지스터 ] : 연산 결과 혹은 CPU 상태에 대한 부가정보를 저장하는 레지스터
[ 프로그램 카운터 ] : 메모리에서 가져올 명령어의주소를 저장하는 레지스터
[ 범용 레지스터 ] : 데이터와 주소를 모두 저장할 수 있는 레지스터
[ 명령어 레지스터 ] : 해석할 명령어를 저장하는 레지스터
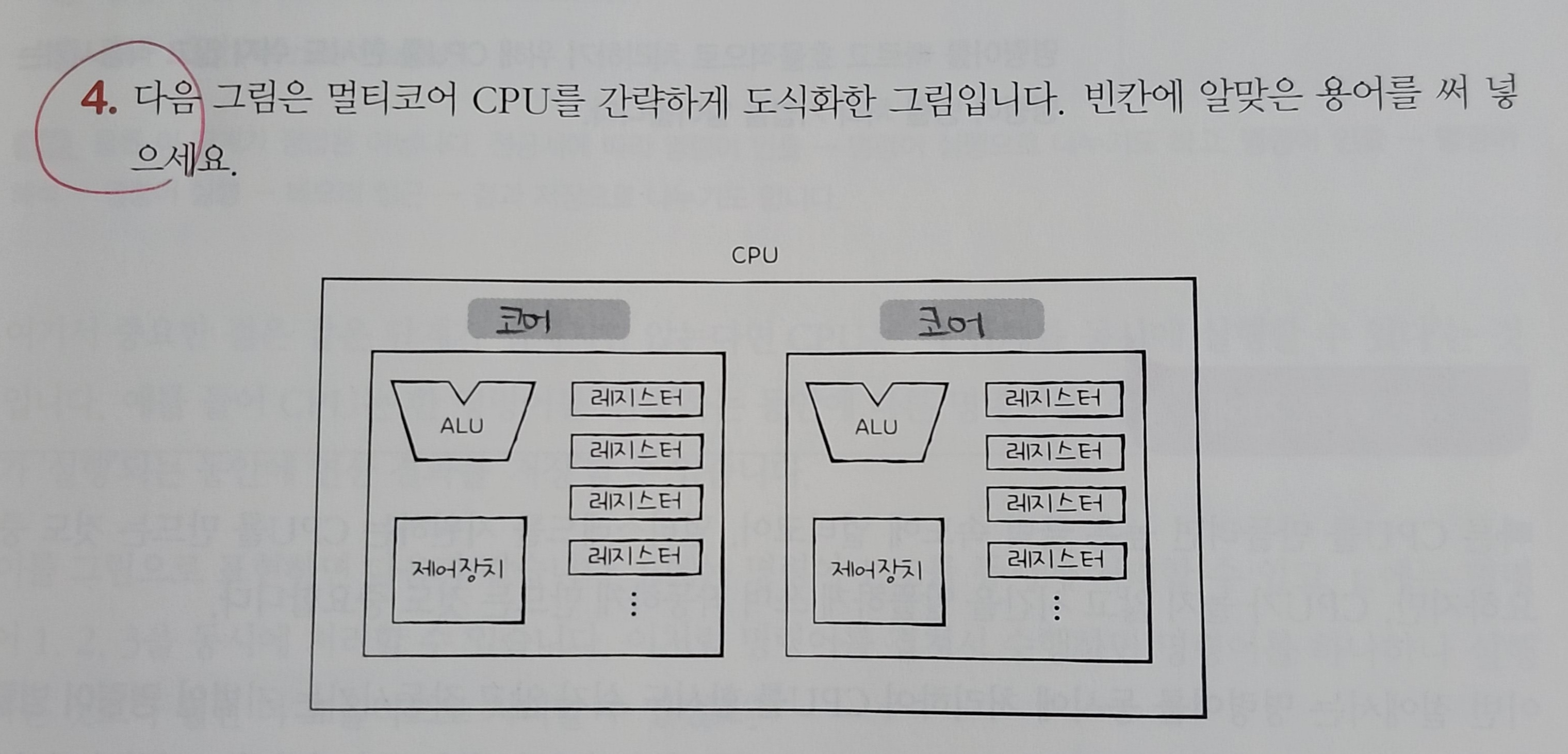
P. 155 확인문제 4
Q. 빈칸에 알맞은 용어를 써 넣으시오.
A.
✍️선택미션
Ch.05(5-1) 코어와 스레드, 멀티 코어와 멀티 스레드의 개념을 정리하기
: 아래 [내용 정리]에서 확인하실 수 있습니다!
🗒️내용 정리
Chap04. CPU의 작동 원리
4.1 ALU와 제어장치
1) ALU
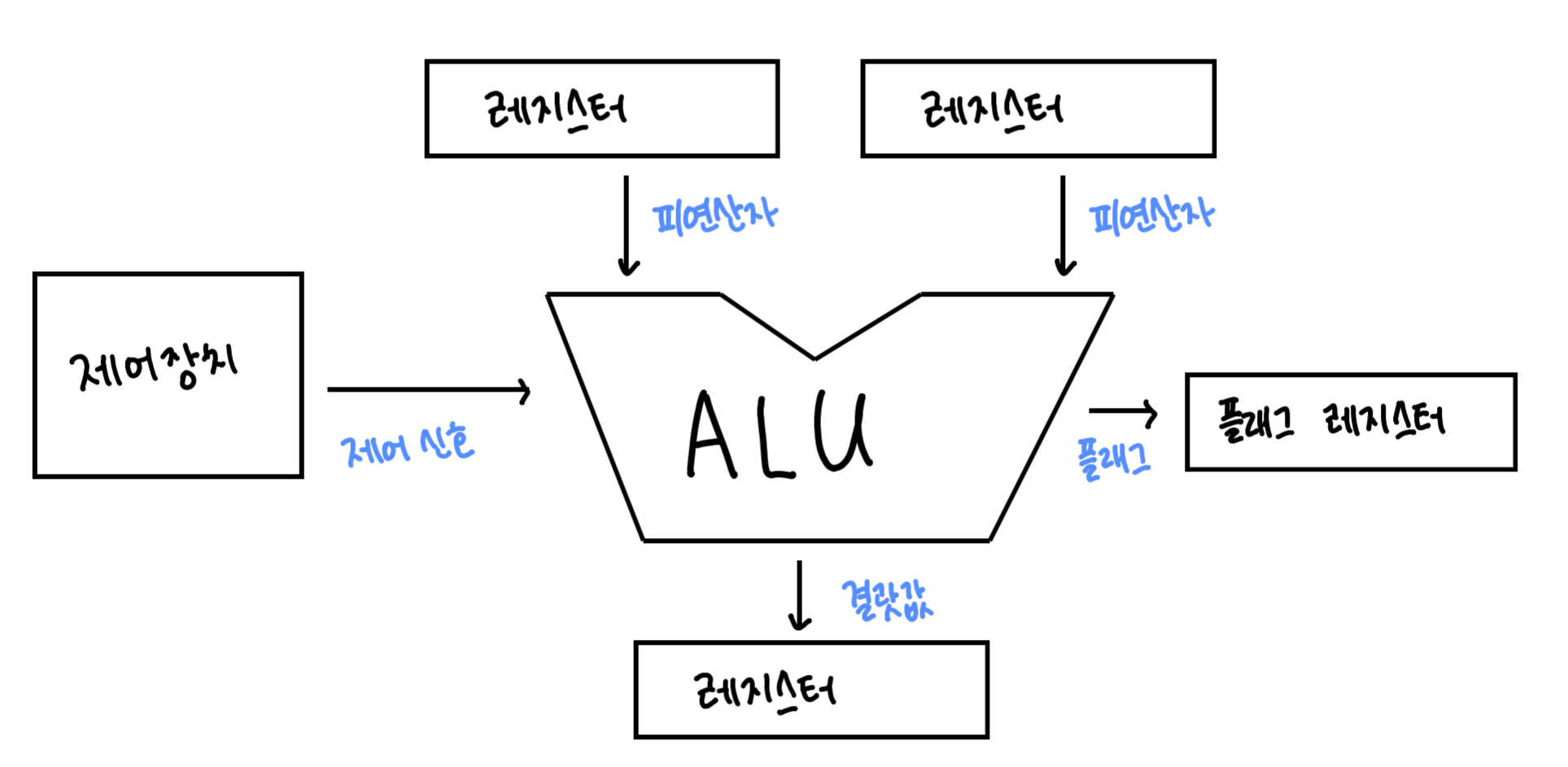
- ALU는 레지스터를 통해 피연산자를 받아들이고, 제어장치로부터 수행할 연산을 알려주는 제어신호를 받아들인다.
- CPU가 메모리에 접근하는 속도는 레지스터에 접근하는 속도보다 훨씬 느리므로 ALU의 결괏값은 레지스터에 저장된다.
- ALU는 계산정보와 더불어 플래그를 내보낸다.
- 플래그 (flag)
- 연산 결과에 대한 추가적인 상태 정보
- 플래그들은 플래그 레지스터에 저장됨.
| 플래그 종류 | 의미 | 사용 예시 |
| 부호 플래그 | 연산한 결과의 부호를 나타냄. | 부호 플래그 : 1 -> 계산결과는 음수 부호 플래그 : 0 -> 계산결과는 양수 |
| 제로 플래그 | 연산 결과가 0인지 여부를 나타냄. | 제로 플래그 : 1 -> 연산 결과가 0 제로 플래그 : 0 -> 연산 결과가 0이 아님. |
| 캐리 플래그 | 연산 결과 올림수나 빌림수가 발생했는지를 나타냄. | 캐리 플래그 : 1 -> 올림수나 빌림수 발생 캐리 플래그 : 0 -> 올림수나 빌림수 발생 x |
| 오버플로우 플래그 | 오버플로우가 발생했는지를 나타냄 | 오버플로우 플래그 : 1 -> 오버플로우 발생 오버플로우 플래그 : 0 -> 오버플로우 발생 x |
| 인터럽트 플래그 | 인터럽트가 가능한지를 나타냄. | 인터럽트 플래그 : 1 -> 인터럽트 가능 인터럽트 플래그 : 0 -> 인터럽트 불가능 |
| 슈퍼바이저 플래그 | 커널 모드로 실행 중인지, 사용자모드로 실행 중인지를 나타냄. | 슈퍼바이저 플래그 : 1 -> 커널 모드로 실행 중임 슈퍼바이저 플래그 : 0 -> 사용자 모드로 실행 중임 |
2) 제어장치
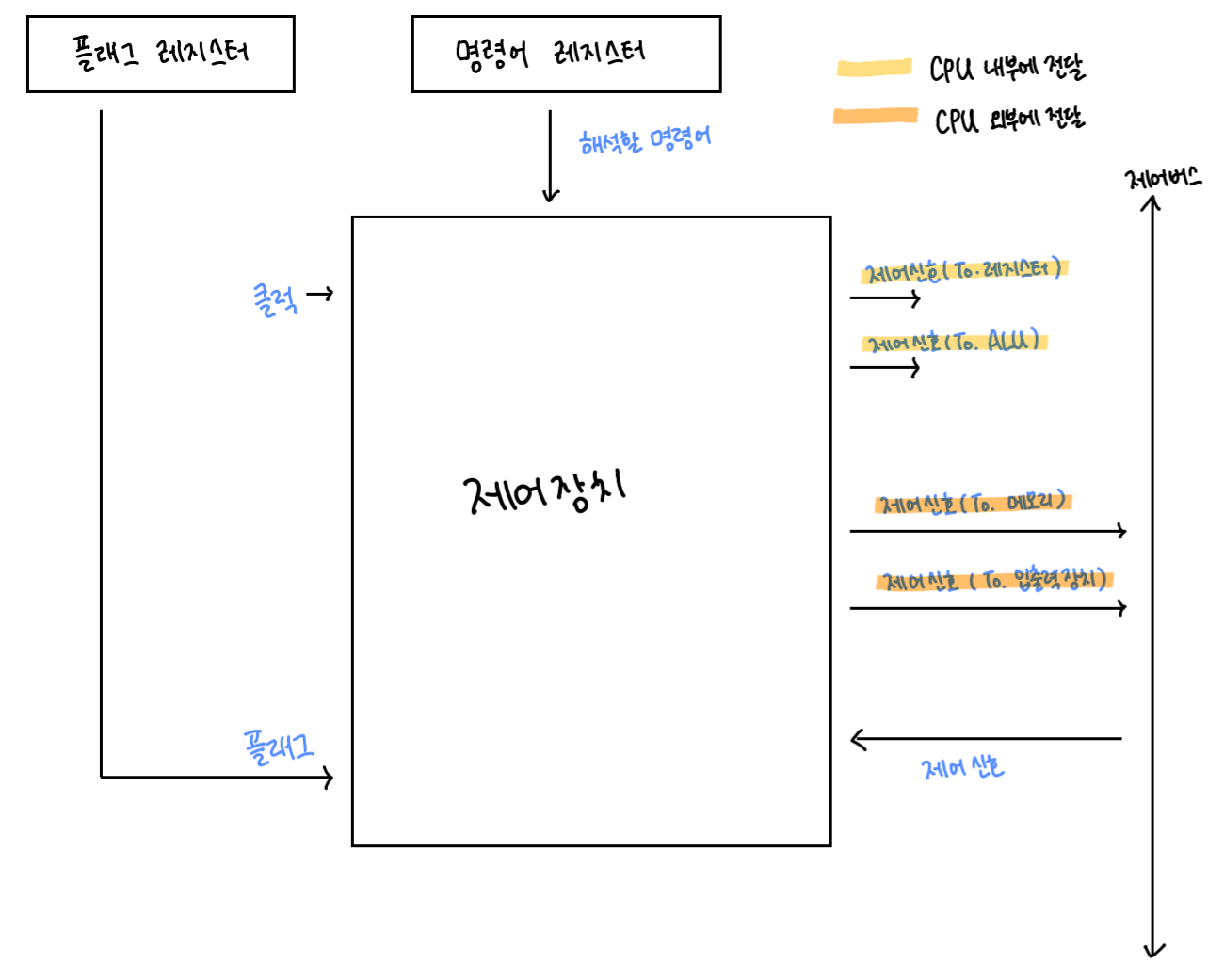
- 제어 신호(컴퓨터 부품을 관리하고 작동시키기 위한 일종의 전기신호)를 내보내고, 명령어를 해석하는 부품
- 제어장치가 받아들이는 정보
- 클럭 신호
- 클럭(clock) : 컴퓨터의 모든 부품을 움직이게 하는 시간 단위
- 해석해야 할 명령어
- CPU가 해석해야 할 명령어는 명령어 레지스터에 저장됨.
- 제어장치는 명령어 레지스터로부터 해석할 명령어를 받아들이고 해석한 뒤 제어신호를 발생시켜 컴퓨터 부품들에게 수행해야 할 내용을 알림.
- 플래그 레지스터 속 플래그 값
- 시스템 버스, 그중에서도 제어 버스로 전달된 제어 신호
- 제어 버스를 통해 외부로부터 전달된 제어 신호를 받아들임.
- 제어장치가 내보내는 정보
- CPU 외부에 전달하는 제어 신호
- 제어 버스로 제어 신호를 내보낸다.
- 메모리에 전달하는 제어 신호와 입출력장치(보조기억장치 포함)에 전달하는 제어 신호가 있음.
- 메모리나 입출력장치의 값을 읽거나 새로운 값을 쓸 때 내보냄.
- CPU 내부에 전달하는 제어 신호
- ALU에 전달하는 제어 신호와 레지스터에 전달하는 제어 신호가 있음.
- ALU에 전달하는 제어 신호 : 수행할 연산을 지시하기 위함.
- 레지스터에 전달하는 제어 신호 : 레지스터 간 데이터를 이동시키거나 레지스터에 저장된 명령어를 해석하기 위함.
4.2 레지스터
1) 반드시 알아야 할 레지스터
(1) 프로그램 카운터 (PC ; Program Counter)
- 메모리에서 가져올 명령어의 주소를 저장
- 변위 주소 지정 방식에 사용되는 레지스터
- 명령어 포인터라고도 부르는 CPU 있음.
(2) 명령어 레지스터 (IR ; Instruction Register)
- 해석할 명령어를 저장하는 레지스터
- 제어장치는 명령어 레지스터 속 명령어를 받아들이고 해석한 뒤 제어신호를 내보냄.
(3) 메모리 주소 레지스터 (MAR ; Memory Address Register)
- 메모리의 주소를 저장하는 레지스터
- CPU가 읽어 들이고자 하는 주소 값을 주소 버스로 내보낼 때 MAR을 거치게 됨.
(4) 메모리 버퍼 레지스터 (MBR ; Memory Buffer Register)
- 메모리와 주고받을 값(데이터, 명령어)을저장하는 레지스터
- 데이터 버스로 주고받을 값이 MBR을 거치게 됨.
- 메모리 데이터 레지스터(MDR ; Memory Data Register)라고도 함.
(5) 플래그 레지스터 (flag register) : 연산 결과 또는 CPU 상태에 대한 부가 정보를 저장하는 레지스터
(6) 범용 레지스터 (general purpose register) : 데이터와 주소 모두 저장이 가능한 레지스터
(7) 스택 포인터 (stack pointer) : 스택 주소 지정 방식에 사용되는 레지스터
(8) 베이스 레지스터 : 변위 주소 지정 방식에 사용되는 레지스터
2) 특정 레지스터를 이용한 주소 지정 방식 1 : 스택 주소 지정 방식
- 스택 주소 지정 방식 : 스택과 스택 포인터를 이용한 주소 지정 방식
- 스택 포인터는 스택에 마지막으로 저장된 값의 위치를 저장함.
- 스택은 메모리 내 스택 영역에 위치함.
3) 특정 레지스터를 이용한 주소 지정 방식 2 : 변위 주소 지정 방식
(1) 변위 주소 지정 방식 (displacement addressing mode)
- 오퍼랜드 필드의 값(변위)과 특정 레지스터의 값을 더해 유효 주소를 얻어내는 주소 지정 방식
- 변위 주소 지정 방식을 사용하는 명령어는 연산 코드 필드, 레지스터 필드, 오퍼랜드 필드가 있음.
- 오퍼랜드 필드의 주소와 어떤 레지스터를 더하는지에 따라 상대 주소 지정 방식, 베이스 레지스터 주소 지정 방식 등으로 나뉨.
(2) 상대 주소 지정 방식 (relative addressing mode)
- 오퍼랜드와 프로그램 카운터의 값을 더하여 유효 주소를 지정하는 방식
- 모든 코드를 실행하는 것이 아니라 분기하여 특정 주소의 코드를 실행할 때 사용됨.
(3) 베이스 레지스터 주소 지정 방식 (base-register addressing mode)
- 오퍼랜드와 베이스 레지스터의 값을 더하여 유효 주소를 얻는 방식
- 베이스 레지스터 속 기준 주소로부터 얼마나 떨어져 있는 주소에 접근할지를 연산해 유효 주소를 얻어냄.
4.3 명령어 사이클과 인터럽트
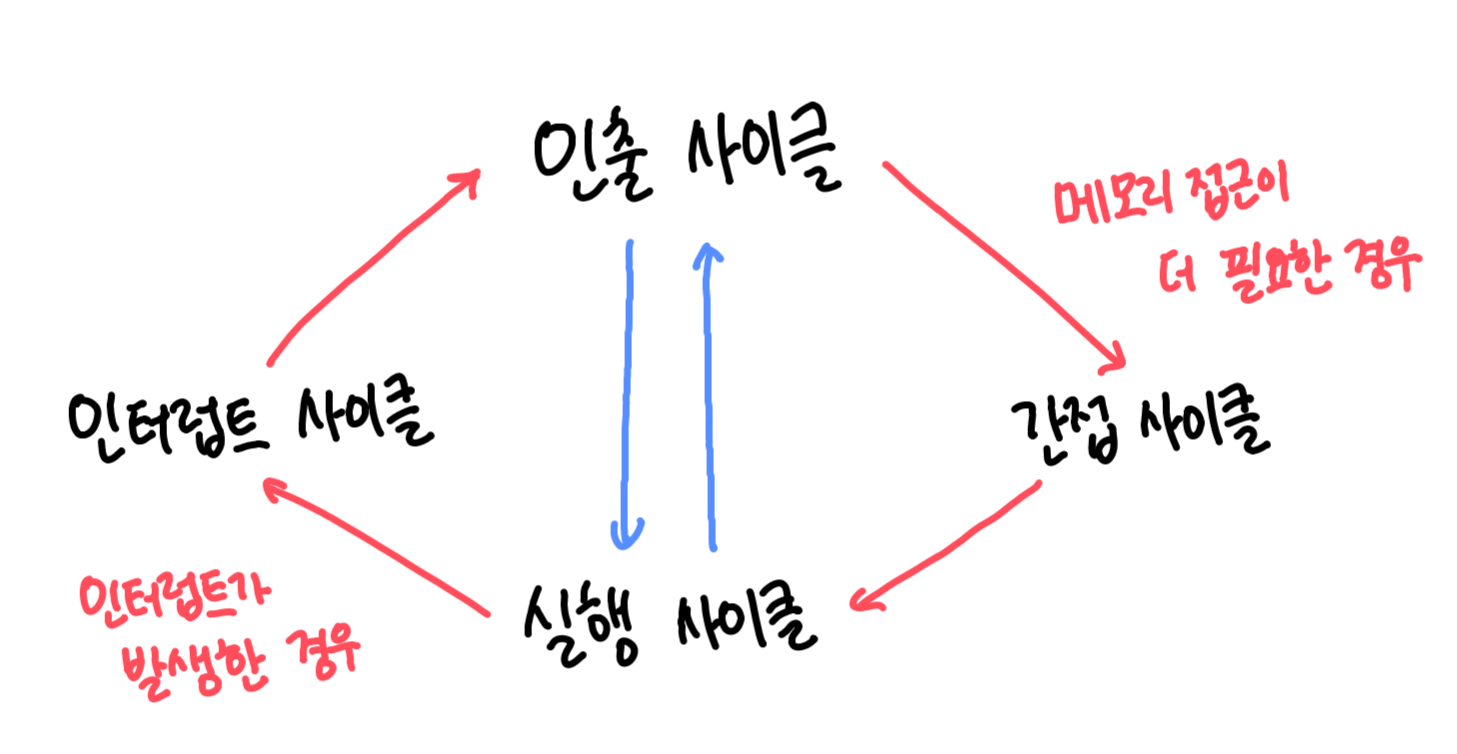
1) 명령어 사이클 (instruction cycle)
- 프로그램 속 각각의 명령어가 반복되며 실행되는 주기
- 프로그램을 이루는 수많은 명령어는 일반적으로 인출과 실행 사이클을 반복하며 실행됨.
- 인출 사이클 (fetch cycle) : 메모리에 있는 명령어를 CPU로 가져오는 단계
- 실행 사이클 (execution cycle) : CPU로 가져온 명령어를 실행하는 단계
- 제어장치가 명령어 레지스터에 담긴 값을 해석하고, 제어신호를 발생시키는 단계
- 간접 사이클 (indirect cycle)
- 명령어를 인출하여 CPU로 가져왔더라도 바로 실행할 수 없는 경우(명령어를 실행하기 위해 추가적인 메모리 접근이 필요)에 거치게됨.
- ex) 간접 주소 지정 방식
2) 인터럽트 (interrupt)
- CPU의 작업을 방해하는 신호
- 비동기 인터럽트와 동기 인터럽트가 있음.
(1) 동기 인터럽트 (synchronous interrupts) == 예외(execption)
- CPU에 의해 발생하는 인터럽트
- CPU가 명령어들을 수행하다가 예외적인 상황이 발생했을 때 발생함
- 예외의 종류
- 폴트 (fault) : 예외를 처리한 직후 예외가 발생한 명령어부터 실행을 재개하는 예외
- 트랩 (trap) : 예외를 처리한 직후 예외가 발생한 명령어의 다음 명령어부터 실행을 재개하는 예외
- 중단 (abort) : CPU가 실행 중인 프로그램을 강제로 중단시킬 수밖에 없는 심각한 오류를 발견했을 때 발생하는 예외
- 소프트웨어 인터럽트 (software interrupt) : 시스템 호출이 발생했을 때
(2) 비동기 인터럽트 (asynchronous interrupts) == 하드웨어 인터럽트
- 주로 입출력장치에 의해 발생
- CPU가 입출력 작업 도중에도 효율적으로 명령어를 처리하기 위해 사용
- 하드웨어 인터럽트 처리 순서
- 입출력 장치는 CPU에 인터럽트 요청 신호를 보냄
- CPU는 실행 사이클이 끝나고 명령어를 인출하기 전에 항상 인터럽트 여부를 확인함.
- CPU는 인터럽트 요청을 확인하고 인터럽트 플래그를 통해 현재 인터럽트를 받아들일 수 있는지 여부를 확인함
- CPU가 인터럽트 요청을 수용하기 위해 플래그 레지스터의 인터럽트 플래그가 활성화되어 있어야 함.
- 인터럽트 플래그(interrupt flag) : 하드웨어 인터럽트를 받아들일지 여부를 결정
- 인터럽트 플래그가 '불가능' -> 보통 요청 무시
- 인터럽트 플래그가 '불가능'으로 되어 있더라도 무시할 수 없는 인터럽트 요청도 있음.
- 막을 수 있는 인터럽트(maskable interrupt) : 인터럽트 플래그로 막을 수 있음
- 막을 수 없는 인터럽트(non maskable interrup) : 인터럽트 플래그로 막을 수 없음
- 인터럽트를 받아들일 수 있다면 CPU는 지금까지의 작업을 백업함.
- 현재 프로그램을 재개하기 위한 모든 내용을 스택에 저장
- CPU는 인터럽트 벡터를 참조하여 인터럽트 서비스 루틴을 실행함.
- 인터럽트 서비스 루틴 (ISR ; Interrput Service Routine)
- 인터럽트를 처리하기 위한 프로그램
- 인터럽트 핸들러(interrupt handler)라고도 함.
- 인터럽트를 처리하는 방법은 입출력장치마다 다르므로 각각의 ISR을 가짐.
- 인터럽트 벡터 (interrupt vector)
- 인터럽트 서비스 루틴을식별하기 위한 정보
- 인터럽트 벡터를 통해 인터럽트 서비스 루틴의 시작 주소를 알 수 있기 때문에 CPU는 인터럽트 벡터를 통해 특정 인터럽트 서비스 루틴을 처음부터 실행할 수 있음.
- 인터럽트 서비스 루틴 (ISR ; Interrput Service Routine)
- 인터럽트 서비스 루틴이 끝나면 4.에서 백업했던 작업을 복구해 실행을 재개함.
Chap05. CPU 성능 향상 기법
5.1 빠른 CPU를 위한 설계 기법
1) 클럭
- 일반적으로 클럭 속도가 높은 CPU는 일반적으로 성능이 좋음.
- Hz 단위로 측정됨.
- CPU는 계속 클럭속도를 유지하기보다는 고성능을 요하는 순간에 순간적으로 클럭속도를 높이고, 그렇지 않을 때 클럭 속도를 낮추기도 한다.
- 오버클락킹(overclocking) : 최대 클럭 속도를 강제로 끌어올리기
2) 코어와 멀티 코어
(1) 코어
- 전통적인 관점에서의 CPU : 명령어를 실행하는 부품이며, 원칙적으로 하나만 존재
- 오늘날의 CPU
- '명령어를 실행하는 부품'에서 '명령어를 실행하는 부품을 여러 개 포함하는 부분'으로 명칭의 개념이 확장됨.
- 코어(core) : '명령어를 실행하는 부품'
(2) 멀티코어
- 멀티코어(multi-core) CPU 또는 멀티코어 프로세서 : 코어를 여러 개 포함하고 있는 CPU
- CPU의 종류 : CPU 안의 코어 개수에 따라 싱글코어(1), 듀얼코어(2), 트리플코어(3), ... 도데카코어(12) 등이 있음.
- CPU의 연산속도가 꼭 코어 개수에 비례하진 않음.
- 코어마다 처리할 명령어들을 얼마나 적절하게 분배하느냐에 따라 CPU의 연산속도가 크게 달라짐.
3) 스레드와 멀티스레드
(1) 스레드
- 스레드(thread) : 실행 흐름의 단위 [사전적 의미]
- 스레드의 종류
- 하드웨어적 스레드 : CPU에서 사용
- 소프트웨어적 스레드 : 프로그램에서 사용
(2) 소프트웨어적 스레드
- 정의 : 하나의 프로그램에서 독립적으로 실행되는 단위
(3) 하드웨어적 스레드
- 정의 : 하나의 코어가 동시에 처리하는 명령어 단위
- 여러 스레드를 지원하는 CPU는 하나의 코어로도 여러 개의 명령어를 동시에 실행할 수 있음.
- 논리 프로세서(logical processor)라고도 함.
(4) 멀티스레드 프로세서
- 멀티스레드(multithread) 프로세서 또는 멀티스레드 CPU : 하나의 코어로 여러 명령어를 동시에 처리하는 CPU
ex) 8코어 16스레드 : 8개의 코어, 코어 하나당 두개의 하드웨어 스레드 처리
- 하나의 코어로 여러 명령어를 동시에 처리하도록 하기 위해서 명령어를 처리하는 데 꼭 필요한 레지스터를 여러 개 갖도록 함.
5.2 명령어 병렬 처리 기법
1) 명령어 파이프라인
(1) 명령어 파이프라인 (instruction pipeline)
- 명령어 인출 (Instruction Fetch)
- 명령어 해석 (Instrcution Decode)
- 명령어 실행 (Execute Instruction)
- 결과 저장 (Write Back)
- 같은 단계가 겹치지 않으면 CPU는 각 단계를 동시에 실행할 수 있음.
- 명령어 파이프라이닝 (instruction pipelining) : 명령어들을 명령어 파이프라인에 넣고 동시에 처리하는 기법
(2) 파이프라인 위험 (pipeline hazard)
- 특정 상황에서는 성능 향상에 실패하는 경우가 있음.
- 데이터 위험 (data hazard)
- 명령어 간 '데이터 의존성'에 의해 발생
- 이전 명령어를 끝까지 실행해야만 비로소 실행할 수 있는 경우
- 데이터 의존적인 두 명령어를 무작정 동시에 실행하려고 하면 파이프라인이 제대로 작동하지 않음.
- 제어 위험 (control hazard)
- 주로 분기 등으로 인한 '프로그램 카운터의 갑작스러운 변화'에 의해 발생
- 프로그램 실행 흐름이 바뀌어 명령어가 실행되면서 프로그램 카운터 값에 갑작스러운 변화가 생기면 명령어 파이프라인에 미리 가지고 와서 처리 중인 명령어가 필요 없어짐.
- 분기 예측 (branch pipeline) : 프로그램이 어디로 분기할지 미리 예측한 후 그 주소를 인출하는 기술
- 구조적 위험 (structural hazard)
- 명령어들을 겹쳐 실행하는 과정에서 서로 다른 명령어가 동시에 같은 CPU 부품을 사용하려 할 때 발생
- 자원 위험(resource hazard)이라고도 함.
2) 슈퍼스칼라 (superscalar)
- CPU 내부에 여러 개의 명령어 파이프라인을 포함한 구조
- 슈퍼스칼라 프로세서 혹은 슈퍼스칼라 CPU : 슈퍼스칼라 구조로 명령어 처리가 가능한 CPU
- 매 클럭 주기마다 동시에 여러 명령어를 인출할 수도, 실행할 수도 있어야 함.
- 이론적으로 파이프라인 개수에 비례하여 프로그램 처리 속도가 빨라짐.
- 파이프라인 위험 등의 예상치 못한 문제로 실제로는 반드시 파이프라인 개수에 비례해 빨라지진 않음.
3) 비순차적 명령어 처리 (OoOE ; Out-of-order execution)
- 정의
: 명령어를 순차적으로만 처리하지 않고 순서를 바꿔 실행해도 무방한 명령어를 먼저 실행하여 명령어 파이프라인을 멈추는 것을 방지하는 기법
- 필요성
- 파이프라인 위험과 같은 예상치 못한 문제들로 인해 이따금씩 명령어는 곧바로 처리되지 못하기도 함
- 모든 명령어들을 순차적으로만 처리한다면 예상치 못한 상황에서 명령어 파이프라인을 멈추게 됨.
- 비순차적 명령어 처리가 가능한 CPU는 명령어들이 어떤 명령어와 데이터 의존성을 가지고 있는지, 순서를 바꿔 실행할 수 있는 명령어에는 어떤 것이 있는지 판단할 수 있어야 함.
5.3 CISC와 RISC
1) 명령어 집합 (instruction set)
- CPU가 이해할 수 있는 명령어들의 모음
- 명령어 집합 구조(ISA ; Instruction Set Architecture)라고도 함.
- CPU마다 ISA가 다를 수 있음.
- ISA가 다르다 → CPU가 이해할 수 있는 명령어가 다름 → 어셈블러어도 달라짐.
- ISA는 CPU의 언어임과 동시에 CPU를 비롯한 하드웨어가 소프트웨어를 어떻게 이해할지에 대한 약속이라고 볼 수 있음.
2) CISC (Complex Instruction Set Computer)
(1) 특징
- 다양하고 강력한 기능의 명령어 집합 이용
- 명령어의 형태와 크기가 다양한 가변 길이 명령어를 활용함.
- 메모리에 접근하는 주소 지정 방식도 다양해서 독특한 주소 지정방식이 있음.
(2) 장점
- 상대적으로 적은 수의 명령어로도 프로그램을 실행할 수 있음. -> 메모리 절약 가능
(3) 한계
- 명령어의 크기와 실행되기까지의 시간이 일정하지 않음.
- 명령어 하나를 실행하는 데 여러 클럭 주기를 필요로 함.
- 파이프라인이 효율적으로 명령어를 처리할 수 없음.
3) RISC (Reduced Instruction Set Computer)
(1) CISC의 한계로 알 수 있는 점
- 빠른 처리를 위해 명령어 파이프라인을 잘 활용해야 한다. 원활한 파이프라이닝을 위해 '명령어 길이와 수행 시간이 짧고 규격화'되어 있어야 함.
- 복잡한 기능을 지원하는 명령어의 사용 빈도가 낮으므로 '자주 쓰이는 기본적인 명령어를 작고 빠르게 만드는 것'이 중요함.
(2) 특징
- 고정 길이 명령어를 활용한다. (짧고 규격화된 명령어, 되도록 1클럭 내에 실행되는 명령어 지향)
- 명령어 파이프라이닝에 최적화되어 있음.
- 메모리에 직접 접근하는 명령어를 load, store 두 개로 제한
- CISC보다 주소 지정 방식이 적은 경우가 많음.
- 이러한 점에서 RISC를 load-store 구조라고도 부름
- 메모리 접근을 단순화, 최소화하고 레지스터를 적극적으로 활용함.
- CISC보다 레지스터를 이용하는 연산이 많음.
- 일반적인 경우보다 범용 레지스터 개수가 많음.
🤔 느낀 점
이번 주 내용도 한 번씩은 간단히 들어본 내용이 꽤 있었습니다. 다만, 평소에 관련 내용에 대해 '왜?'라는 생각을 종종 했는데 그 의문을 해결할 수 있었던 한 주였습니다.👍
'독학 > [책] 컴퓨터구조 + 운영체제' 카테고리의 다른 글
| [혼공학습단 11기 혼공컴운💿] 컴퓨터구조+운영체제 week6 (2) | 2024.02.05 |
|---|---|
| [혼공학습단 11기 혼공컴운💿] 컴퓨터구조+운영체제 week5 (0) | 2024.01.31 |
| [혼공학습단 11기 혼공컴운💿] 컴퓨터구조+운영체제 week4 (0) | 2024.01.22 |
| [혼공학습단 11기 혼공컴운💿] 컴퓨터구조+운영체제 week3 (0) | 2024.01.16 |
| [혼공학습단 11기 혼공컴운💿] 컴퓨터구조+운영체제 week1 (0) | 2024.01.03 |