📝 기본 숙제
Ch.04(04-2) KerasNLP 또는 허깅페이스 BERT 모델로 영화 리뷰 감성 분석 후 결과 캡처하기
아래 내용 정리에서 확인하실 수 있습니다!
📘 추가 숙제
Ch.04(04-2) 감성 분석에 사용된 토큰화 과정 살펴보고 입력과 출력 비교해 보기
🔍 토큰화가 일어나는 코드
prep_data = classifier.preprocessor(feature)🔍 토큰화 입력 : 원래 문장의 앞 100글자 출력
print(feature.numpy()[:100])
🔍 토큰화 출력 : 토큰 ID 출력
print(len(prep_data['token_ids']), prep_data['token_ids'][:10])
prep_data['token_ids'][-10:]
🔍 토큰화 출력 : 토큰 ID ➡️ 토큰 (단어) 변환
tokens = []
for id in prep_data['token_ids'][:10]:
tokens.append(bert_tokenizer.id_to_token(id))
print(tokens)
🔍 토큰화 출력 : 토큰 ➡️ ID 확인 (역변환)
for token in tokens:
print(bert_tokenizer.token_to_id(token), end=' ')
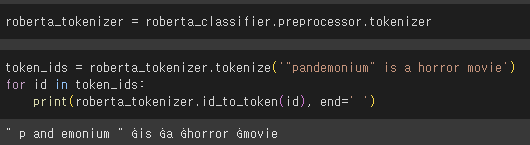
🔍 직접 문자열 토큰화 테스트
bert_tokenizer.tokenize('"pandemonium" is a horror movie')
🗂️ 내용 정리
Chap04-1 트랜스포머 인코더 모델 이해하기
1. 어텐션 매커니즘
1) 어텐션
- 모델에 입력된 데이터의 모든 단어들 중에서 특정 단어와 관련이 높은 단어에 집중해 데이터를 처리하도록 설계된 기법
- 셀프 어텐션 (self attention) : 문장의 모든 단어가 서로를 참고해 각각 다른 단어와의 관련성을 파악하는 방법
- 멀티 헤드 어텐션 (multi-head attention) : 여러 개의 셀프 어텐션(헤드)을 동시에 수행해 이 관련성을 다양한 관점에서 깊이 이해할 수 있도록 확장
- 문맥 벡터(context vector) : 기계 번역에서 인코더 RNN은 먼저 입력된 문장을 처리해 최종 은닉 상태(hidden state)로 만듦
- 디코더 RNN이 인코더로부터 받은 문맥 벡터를 이용해 새로운 문장(번역된 문장)을 만듦.

- 긴 문장일수록 문맥 벡터만으로는 오래된 단어의 정보를 기억하기 어려움 = 그레이디언트가 타임스텝에 걸쳐 전파되며 점점 약해짐
- 인코더의 마지막 타임스텝에서 얻은 은닉 상태뿐만 아니라 인코더의 모든 은닉 상태를 디코더가 텍스트를 생성할 때마다 참고하도록 만듦. = 디코더가 모든 타임스텝에서 인코더의 은닉 상태를 참고해 문맥 벡터를 만듦.


- 트랜스포머 (transformer)
- 순환 신경망에 어텐션을 추가하는 것이 아니라 어텐션만으로 만드는 인코더-디코더 모델

2) 셀프 어텐션
- 입력 토큰 : 모델에 입력하련느 텍스트를 잘게 나눈 단위
- 임베딩 : 신경망이 입력토큰을 처리할 수 있도록 고정 크기의 벡터로 변환
➡️ 디코더의 은닉 상태 없이 입력 토큰만으로 어텐션 점수를 계산하기 때문에 셀프 어텐션이라 함.
- 스케일드 점곱 어텐션을 사용함.
1️⃣ 입력을 세 개의 다른 벡터로 변환
- 쿼리, 키, 값 벡터로 만듦.
- 쿼리 : 이 단어가 어떤 정보를 찾고 있는지 ; 계산의 기준
- 키 : 가지고 있는 정보가 무엇인지 ; 비교의 기준
- 값 : 이 정볼르 제공하면 어떤 결과가 나오는지 ; 실제 정보의 내용
2️⃣ 벡터 간 관계 (유사도) 및 최종 결과 계산
- 각각의 벡터들이 얼마나 관련 있는지 계산
- 키에 대한 점곱 수행
- 임베딩 길이의 제곱근으로 나눠 스케일링
- 각 단어에 계산된 중요도를 확률처럼 확인할 수 있도록 소프트맥스 함수에 통과시켜 합이 1이 되도록 어텐션 함수를 정규화
- 마지막으로 계산된 어텐션 점수와 값 벡터를 곱함.

3) 멀티 헤드 어텐션
1️⃣ 어텐션 계산 : 각각의 헤드가 독립적으로 셀프 어텐션을 수행하고, 각 헤드에서 계산된 출력을 하나로 연결
2️⃣ 최종 변환 : 하나로 연결될 멀티 헤드 어텐션의 결과를 밀집층에 통과시켜 원본 임베딩 크기로 변환
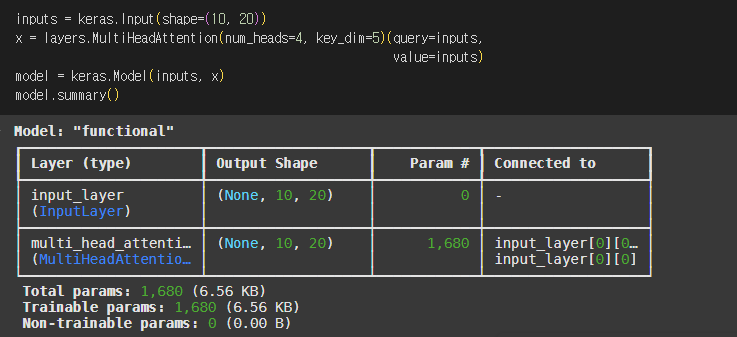
2. 위치 인코딩과 층 정규화
1) 순서 정보 더하기 - 위치 인코딩 (PE; Positional Encoding)
- 토큰과 토큰 사이의 거리르 감지하지 못함 ➡️ 단어의 순서에 대한 정보를 보완하기 위해 토큰 임베딩에 위치 인코딩 추가


2) 훈련 안정화하기 - 층 정규화 (layer normalization)
- 배치 단위가 아니라 각 샘플의 특성을 정규화
- 텍스트 시퀸스에 있는 토큰마다 정규화하는 것으로 자연어 처리 작업에 더욱 적합


3. 트랜스포머 인코더 모델 만들기

- 멀티 헤드 어텐션층 다음에는 과대적합을 막기 위해 훈련 단계에서 뉴런의 일부를 무작위로 비활성화하는 드룹아웃 층이 놓임
- 드롭아웃층의 출력은 어텐션의 입력과 더해져 층 정규화를 통과함
- 위치별 피드 포워드 네트워크 또는 피드 포워드 네트워크
- 첫 번째 밀집층 : 입력 벡터의 차원을 확장, 렐루 활성화 함수 사용
- 두 번째 밀집층 : 다시 원래의 임베딩 차원으로 축소, 활성화 함수 미사용
- 스킵 연결 직전에 토과하는 드롭아웃층은 잔차 드롭아웃이라고 함.
- 원본 트랜스포머 모델은 어텐션층에서 소프트맥스 함수의 출력에도 드롭아웃을 적용 ; 어텐션 드롭아웃

Chap04-2 전이 학습으로 영화 리뷰 텍스트의 감정 분류하기
1. 트랜스포머 인코더 기반 언어 이해 모델 - BERT
- BERT : 트랜스포머 인코더 기반의 대규모 언어 모델 (LLM)
- 훈련
- 마스크드 언어 모델링(MLM) : 입력 데이터의 일부 토큰을 가린(마스킹) 다음, 모델이 가려진 단어를 예측
- 다음 문장 예측(NSP) : 두 문장이 제시됐을 때 두 번째 문장이 첫 번째 문장에 이어지는 다음 문장인지를 예측
- 백본(backbone) : 학습된 출력 벡터를 기반으로 수행되는 별도의 분류기

- KerasNLP


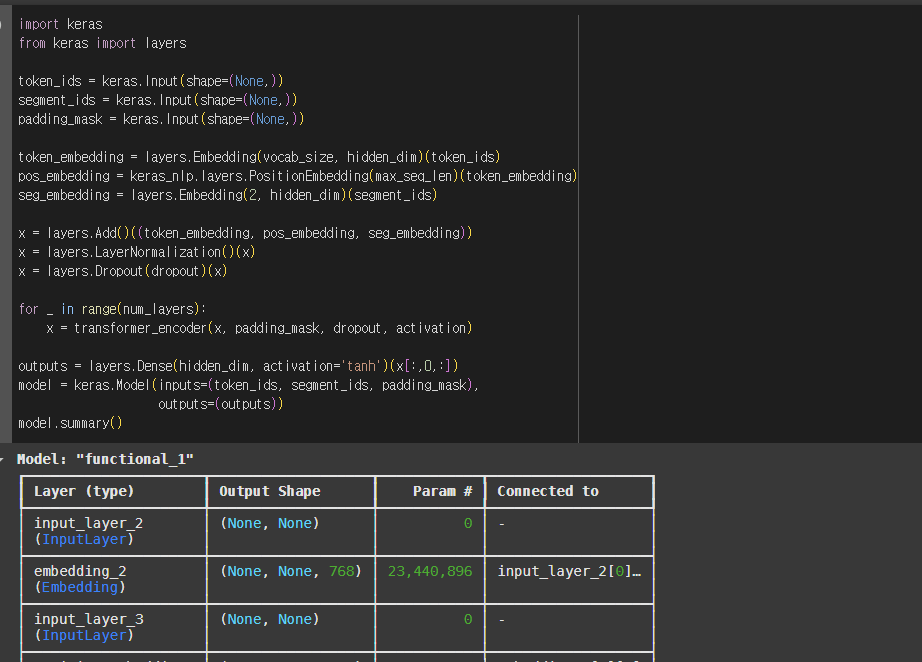
2. KerasNLP로 영화 리뷰 텍스트의 감성 분류하기
(1) KerasNLP로 BERT 모델 로드하기


(2) BERT 모델 미세튜닝하기




(3) 텍스트 전처리하기 - BERT 토크나이저
- 토큰화 : 언어 모델이 텍스트 문자열을 모델이 처리할 수 있는 작은 부분(토큰)으로 분리하는 과정
- 어휘사전 : 고유한 토큰의 집합
- 토크나이저 : 토큰화를 수행하는 방법 또는 객체
- BERT 토크나이저는 워드피스 토큰화를 사용



3. 허깅페이스로 영화 리뷰 텍스트의 감성 분류하기
1) 네이버 영화 리뷰 데이터셋 준비하기



2) 백본 모델 선택하기


3) 입력 데이터 토큰화하기



4) BERT 모델 미세 튜닝하기

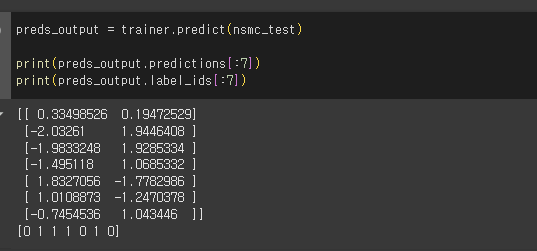
4. 미세 튜닝된 모델로 감성 분석하기
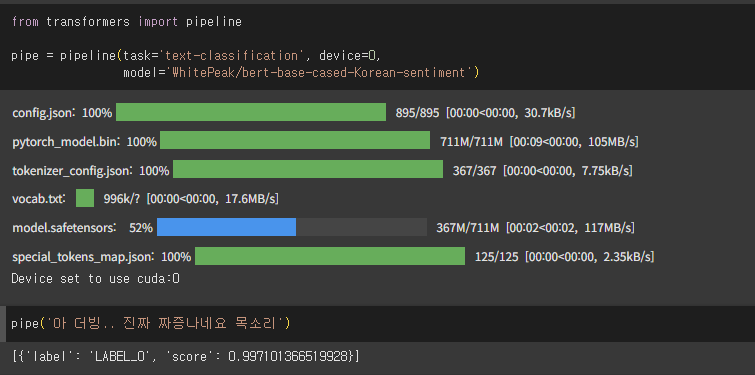
Chap04-3 BERT 후속 모델로 영화 리뷰 텍스트의 감성 분류하기
1. BERT의 성능 개선 모델 - RoBERTa
1) RoBERTa
- BERT의 사전 훈련 방식을 재구성해 더 많은 데이터를 활용하고, 훈련 설정을 최적화함으로써 성능을 크게 개선
- 사전 훈련 방식에서 다음 문장 예측(NSP) 작업을 제거하고, 마스크드 언어 모델링만 사용하여 모델을 훈련
- BERT의 워드피스 토크나이저 대신, 바이트 수준의 바이트 페어 인코딩(BPE) 토크나이저를 사용

2) KerasNLP로 RoBERTa 모델 만들기


3) RoBERTa 모델 미세 튜닝하기



2. BERT의 경량화 모델 - DistilBERT
1) DistilBERT
- BERT의 경량화 모델
- 지식정제 (knowledge distillation) : 더 큰 모델인 티처 모델이 학습한 지식을 더 작은 모델인 스튜던트 모델에 전달
- 마스크드 언어 모델링 작업에서 스튜던트의 출력이 티처의 출력에 가까워지도록 스튜던트를 훈련하는 것이 지식 정제의 핵심
- 정제 손실 : 두 모델의 출력 차이로 인한 손실
2) 티처 모델 이해하기 - MLM을 위한 BERT


3) 정제 손실 이해하기
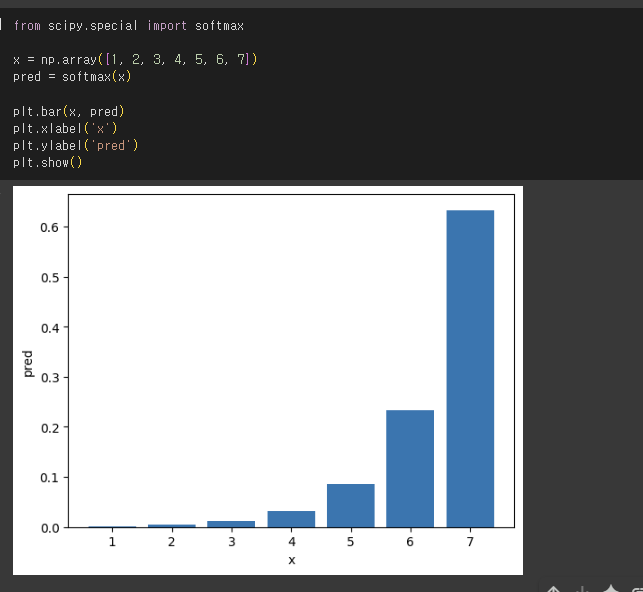
- 티처와 스튜던트 모델의 출력 값을 소프트맥스 함수에 통과시켜 확률분포로 변환한 뒤에 비교 ➡️ 쿨백-라이블러 발산(KLD) 손실
teacher_pred = softmax(teacher_output)
student_pred = softmax(student_output)
KLD_loss = teacher_pred * log(teacher_pred / student_pred)


4) 스튜던트 모델 DistilBERT 사용하기



5) DistilBERT로 IMDB 영화 데이터 리뷰 텍스트의 감성 분류하기



3. KerasNLP로 DistilBERT 모델 만들기


💭 느낀 점
후반부라 그런지 지금까지 혼공학습단 스터디하면서 가장 많은 공부 시간을 들인 주차였습니다.. 이렇게 6주 활동이 끝났는데 수고 많으셨습니다!
'독학 > [책] 딥러닝 실습' 카테고리의 다른 글
| [혼공학습단 14기 혼만딥🧠] 혼자 만들면서 공부하는 딥러닝 week5 (3) | 2025.08.06 |
|---|---|
| [혼공학습단 14기 혼만딥🧠] 혼자 만들면서 공부하는 딥러닝 week4 (1) | 2025.07.23 |
| [혼공학습단 14기 혼만딥🧠] 혼자 만들면서 공부하는 딥러닝 week3 (1) | 2025.07.15 |
| [혼공학습단 14기 혼만딥🧠] 혼자 만들면서 공부하는 딥러닝 week2 (0) | 2025.07.08 |
| [혼공학습단 14기 혼만딥🧠] 혼자 만들면서 공부하는 딥러닝 week1 (2) | 2025.07.01 |