저번에 책으로 SQL를 공부했는데 이번에는 인강을 통해서 한 번 더 내용을 빠르게 정리하려고 한다. 무료강의의 경우 공개글로, 유료강의의 경우에는 보호글로 올릴 예정이다.
인강은 아래 강의이다.
갖고노는 MySQL 데이터베이스 by 얄코 강의 - 인프런
비전공자도 이해할 수 있는 MySQL! 빠른 설명으로 필수개념만 훑은 뒤 사이트의 예제들과 함께 MySQL을 ‘갖고 놀면서’ 손으로 익힐 수 있도록 만든 강좌입니다., 빠르게 배우고, 손으로 익히고!
www.inflearn.com
1. SELECT 전반 기능 훏어보기
1.1 테이블의 모든 내용 보기
- * : 테이블의 모든 column
SELECT * FROM Customers;
-- Customers에서 모든 column을 가져온다1.2 원하는 column만 골라서 보기
SELECT CustomerName FROM Customers;
-- CustomerS에서 CustomerName 열만 가져온다SELECT CustomerName, ContactName, Country
FROM Customers;
-- 여러 개의 열을 가져오기- 테이블의 컬럼이 아닌 값도 선택할 수 있다.
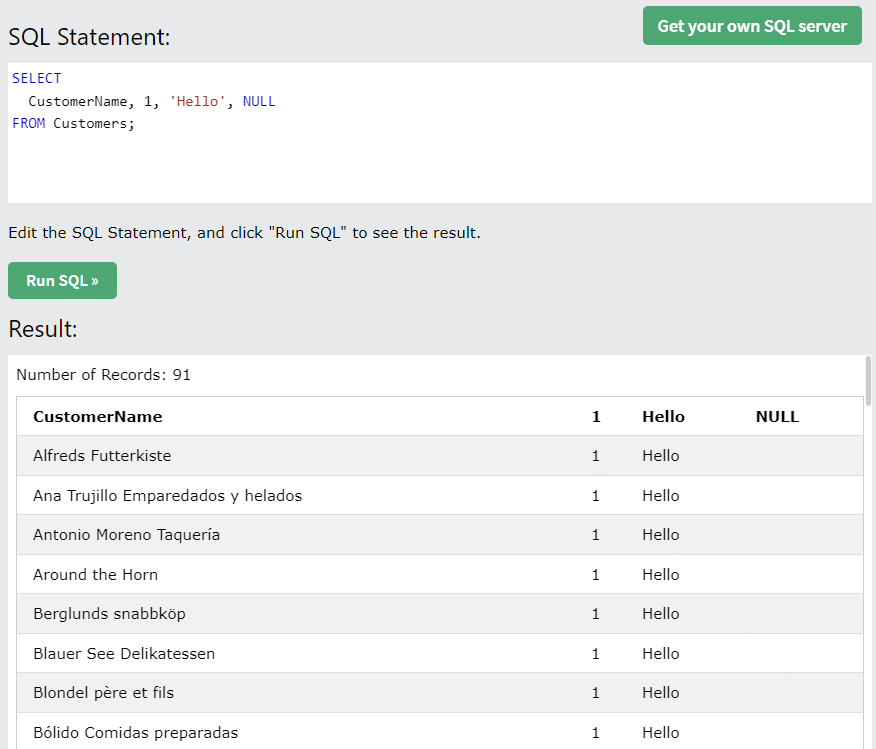
1.3 원하는 조건의 row(행)만 걸러서 보기
- WHERE 조건 : 조건에 해당하는 행만을 가져오기

1.4 원하는 순서로 데이터 가져오기
- ORDER BY 컬럼 [ASC/DESC]
- ASC : 오름차순, 기본
- DESC : 내림차순

1.5 원하는 만큼만 데이터 가져오기
- 전체 데이터를 가져올 때 서버의 무리가 올 수 있으니 사용
- LIMIT (가져올 행의 개수)
- LIMIT (건너뛸 행의 개수), (가져올 행의 개수)

1.6 원하는 별명(alias)으로 데이터 가져오기
- 열 AS 별명 : column명을 변경할 수 있다.

2. 각종 연산자들
- 문자열에 대한 대소문자 구분을 하지 않는다.
- 문자열에 사칙연산을 하면 0으로 인식
- 문자열이 숫자로 구성되어 있으면 숫자로 인식
- TRUE(1), FALSE(0)
| +, -, *, / | 더하기, 빼기, 곱하기, 나누기 |
| %, MOD | 나머지 |
| IS | 양쪽이 모두 TRUE이거나 FALSE |
| IS NOT | 한쪽은 TRUE, 한쪽은 FALSE |
| AND, && | 양쪽이 모두 TRUE여야 TRUE |
| OR, || | 양쪽 중 하나가 TRUE면 TRUE |
| = | 양쪽이 같다 |
| !=, <> | 양쪽이 다르다 |
| >, < : | (왼쪽, 오른쪽) 값이 더 크다 |
| >=, <= | (왼쪽, 오른쪽) 값이 더 크거나 같다. |
| BETWEEN {MIN} AND {MAX} | MIN <= 값 <= MAX |
| NOT BETWEEN {MIN} AND {MAX} | MIN > 값 이거나 값 > MAX |
| IN (...) | 괄호 안의 값 중 하나 |
| NOT IN (...) | 괄호 안의 값에 해당하지 않음 |
| LIKE '...%...' | 0~N개의 문자를 가진 패턴 |
| LIKE '..._...' | _ 개수만큼의 문자를 가진 패턴 |
3. 숫자와 문자열을 다루는 함수들
3.1 숫자 관련 함수들
- ROUND(숫자) : 반올림
- CEIL(숫자) : 올림
- FLOOR(숫자) : 내림
- ABS(숫자) : 절대값
- GREATEST(숫자, 숫자, ...) : 괄호 안에서 가장 큰 값
- LEAST(숫자, 숫자, ...) : 괄호 안에서 가장 작은 값
- POW(A, B), POWER(A, B) : A의 B제곱
- SQRT(숫자) : 제곱근
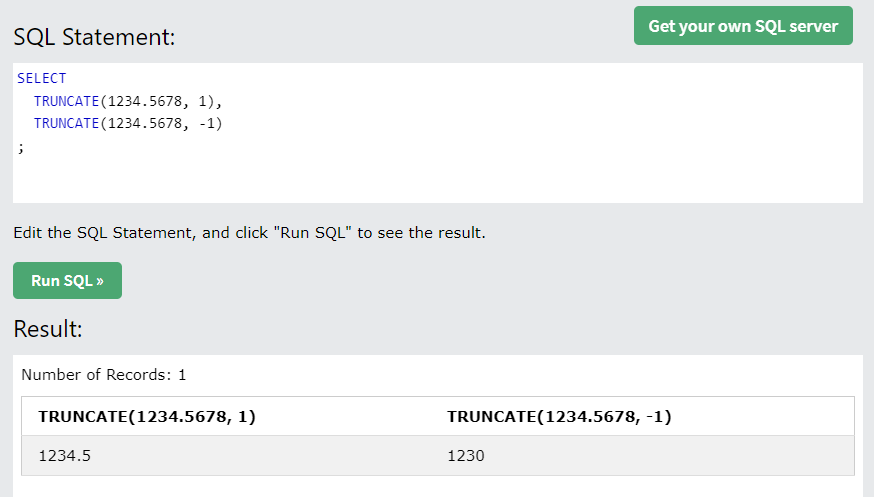
- TRUNCATE(N, n) : N을 소수점 n자리까지 선택(n이 음수일 경우 정수부를 선택)
- 그룹 함수 : 조건에 따라 집계된 값을 가져온다.
- MAX : 가장 큰 값
- MIN : 가장 작은 값
- COUNT : 갯수 (NULL 제외)
- SUM : 총합
- AVG : 평균 값
3.2 문자열 관련 함수들
- UCASE, UPPER : 모두 대문자로
- LCASE, LOWER : 모두 소문자로
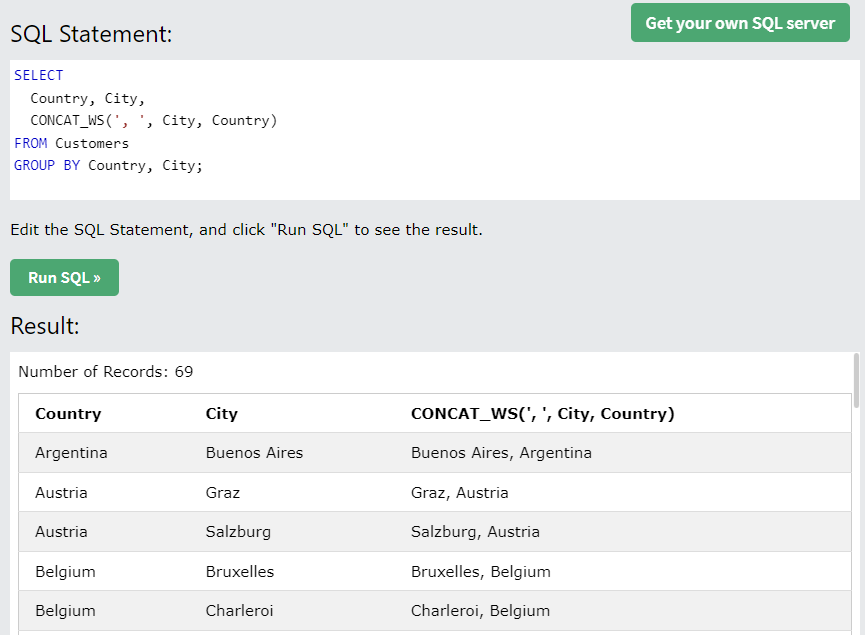
- CONCAT(...) : 괄호 안의 내용을 전부 이어붙임
- CONCAT_WS(s, ...) : 괄호 안의 내용을 s로 이어붙임.
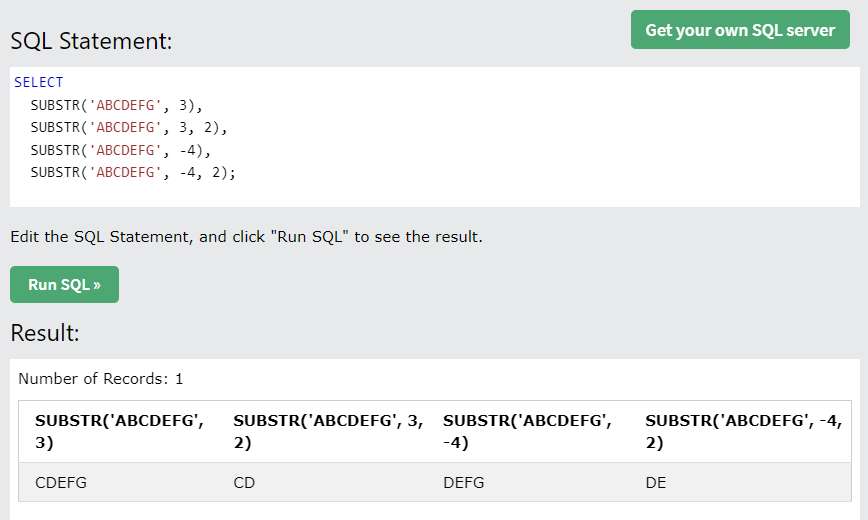
- SUBSTR(), SUBSTRING() : 주어진 값에 따라 문자열을 자름
- LEFT(n) : 왼쪽부터 n글자로 문자열을 자름
- RIGHT(n) : 오쪽부터 n글자로 문자열을 자름
- LENGTH : 문자열의 바이트 길이
- CHAR_LEGTH, CHARACTER_LENGTH : 문자열의 문자 길이
- TRIM : 양쪽 공백 제거
- LTRIM : 왼쪽 공백 제거
- RTRIM : 오른쪽 공백 제거
- LPAD(S, N, P) : S가 N글자가 되도록 왼쪽에 P를 계속 이어붙임.
- RPAD(S, N, P) : S가 N글자가 되도록 오른쪽에 P를 계속 이어붙임.
- REPLACE(S, A, B) : S 속에서 A를 B를 변경
- INSTR(S, s) : S 중 s의 첫 위치를 반환한다. (없으면 0)
- CAST(A AS T), CONVERT (A AS T) : A를 T 자료형으로 변환
4. 시간/날짜 관련 및 기타 함수들
4.1 시간/날짜 관련 함수들
- CURRENT_DATE, CURDATE : 현재 날짜 반환
- CURRENT_TIME, CURTIME : 현재 시간 반환
- CURRENT_TIMESTAMP, NOW : 현재 시간과 날짜 반환
- DATE : 문자열에 따라 날짜 생성
- TIME : 문자열에 따라 시간 생성
- YEAR: 주어진 DATETIME값의 년도 반환
- MONTHNAME : 주어진 DATETIME값의 월(영문) 반환
- MONTH : 주어진 DATETIME값의 월 반환
- WEEKDAY : 주어진 DATETIME값의 요일값 반환(월요일: 0)
- DAYNAME : 주어진 DATETIME값의 요일명 반환
- DAYOFMONTH, DAY : 주어진 DATETIME값의 날짜(일) 반환
- HOUR : 주어진 DATETIME의 시 반환
- MINUTE : 주어진 DATETIME의 분 반환
- SECOND : 주어진 DATETIME의 초 반환
- ADDDATE, DATE_ADD : 시간/날짜 더하기
- SUBDATE, DATE_SUB : 시간/날짜 빼기
- DATE_DIFF : 두 시간/날짜 간 일수차
- TIME_DIFF : 두 시간/날짜 간 시간차
- LAST_DAY : 해당 달의 마지막 날짜
- DATE_FORMAT : 시간/날짜를 지정한 형식으로 반환
- %Y : 년도 4자리
- %y : 년도 2자리
- %M : 월 영문
- %m : 월 영문
- %D : 일 영문(1st, 2nd, 3rd...)
- %d, %e : 일 숫자 (01 ~ 31)
- %T : hh:mm:ss
- %r : hh:mm:ss AM/PM
- %H, %k : 시 (~23)
- %h, %l : 시 (~12)
- %i : 분
- %S, %s : 초
- %p : AM/PM
- STR _ TO _ DATE(S, F) : S를 F형식으로 해석하여 시간/날짜 생성
4.2 기타 함수들
- IF(조건, T, F) : 조건이 참이라면 T, 거짓이면 F 반환
- IFNULL(A, B) : A가 NULL일 시 B 출력
5. 조건에 따라 그룹으로 묶기
5.1 GROUP BY : 조건에 따라 집계된 값을 가져옴.
- 여러 column을 기준으로 그룹화할 수 있다.
- WITH ROLLUP : 전체의 집계값 (ORDER BY와는 함께 사용될 수 없다.)
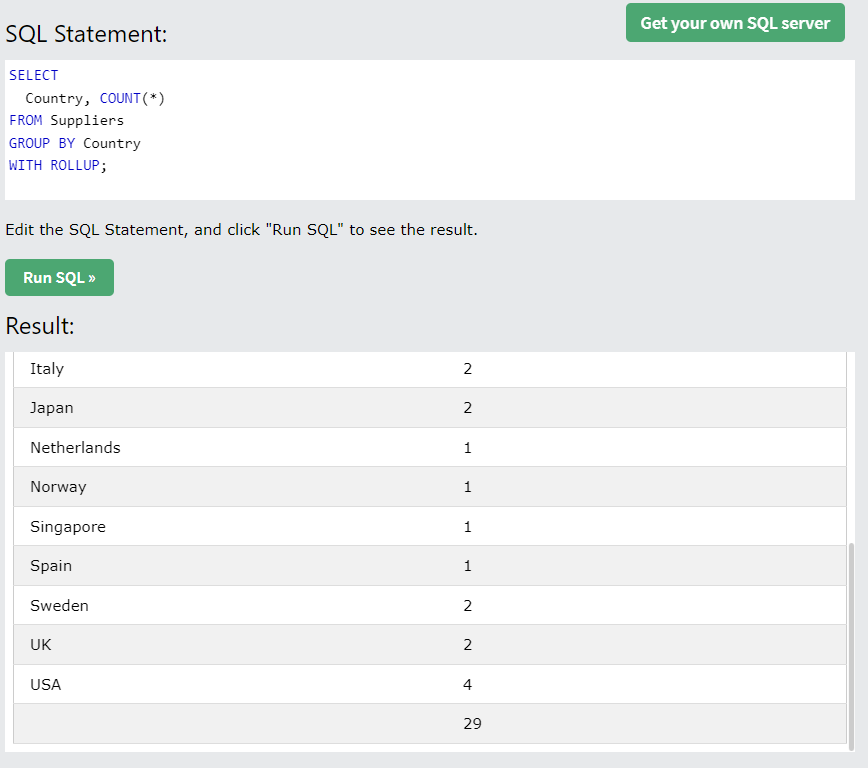
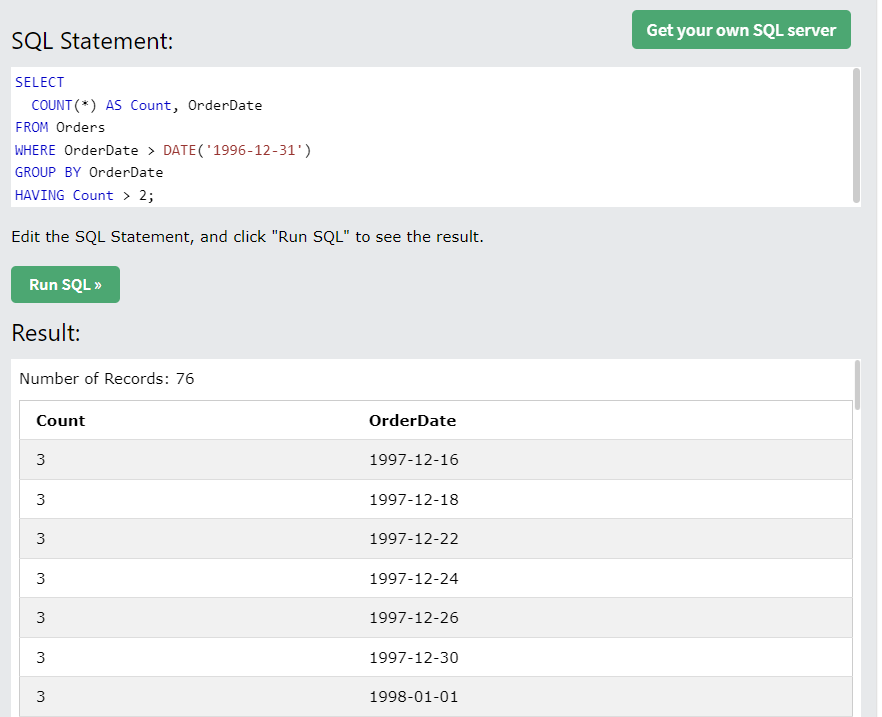
5.2 HAVING : 그룹화된 데이터 걸러내기
- WHERE은 그룹화하기 전, HAVING은 그룹화 집계에 사용
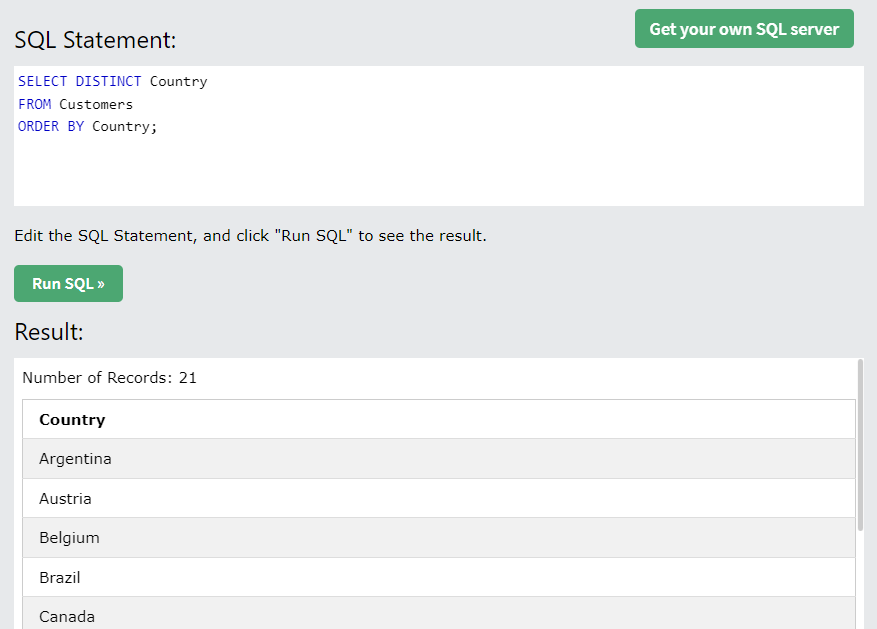
5.3 DISTINCT : 중복된 값 제거
- GRUOP BY와 달리 집계 함수 사용X
- GRUOP BY와 달리 정렬하지 않아서 속도가 더 빠르다.
'독학 > [책 + 인강] SQL' 카테고리의 다른 글
| [얄코 MySQL] 섹션 3 데이터 조작하기 (0) | 2024.04.05 |
|---|---|
| [얄코 MySQL] 섹션 2 SELECT 더 깊이 파보기 (0) | 2024.04.05 |
| [SQL Server] Do it SQL 입문 5장 다양한 SQL 함수 사용하기 (0) | 2024.02.19 |
| [SQL Server] Do it SQL 입문 4장 테이블을 서로 조합하는 조인 알아보기 (0) | 2024.02.04 |
| [SQL Server] Do it SQL 입문 3장 SQL 시작하기 (2) | 2024.01.29 |