📜기본 숙제 : k-평균 알고리즘 작동 방식 설명하기
1️⃣ 무작위로 k개의 클러스터 중심을 정한다.
2️⃣ 각 샘플에서 가장 가까운 클러스터 중심을 찾아 해당 클러스터의 샘플로 지정한다.
3️⃣ 클러스터에 속한 샘플의 평균값으로 클러스터 중심을 변경한다.
4️⃣ 클러스터 중심에 변화가 없을 때까지 2번으로 돌아가 반복한다.
📜 추가 숙제 : Ch.06(06-3) 확인 문제 풀고, 풀이 과정 정리하기
Q1. 특성이 20개인 대량의 데이터셋이 있습니다. 이 데이터셋에서 찾을 수 있는 주성분의 개수는 몇 개일까요?
A1. 20
;특성의 개수만큼 주성분을 찾을 수 있다.
Q2. 샘플 개수가 1000개이고 특성 개수는 100개인 데이터셋이 있습니다. 즉 이 데이터셋의 크기는 (1000, 100)입니다. 이 데이터를 사이킷런의 PCA 클래스를 사용해 10개의 주성분을 찾아 변환했습니다. 변환된 데이터셋의 크기는 얼마일까요?
A2.(1000, 10)
; 샘플 개수는 동일하고 특성 개수는 10으로 바뀐다.
Q3. 2번 문제에서 설명된 분산이 가장 큰 주성분은 몇 번째인가요?
A3. 첫 번째 주성분
; 가장 분산이 큰 방향부터 순서대로 찾는다.
🔖 Chap06. 비지도 학습
6.1 군집 알고리즘
1) 타깃을 모르는 비지도 학습
- 데이터 준비하기

- 픽셀값 분석하기

2) 평균값과 가까운 사진 고르기
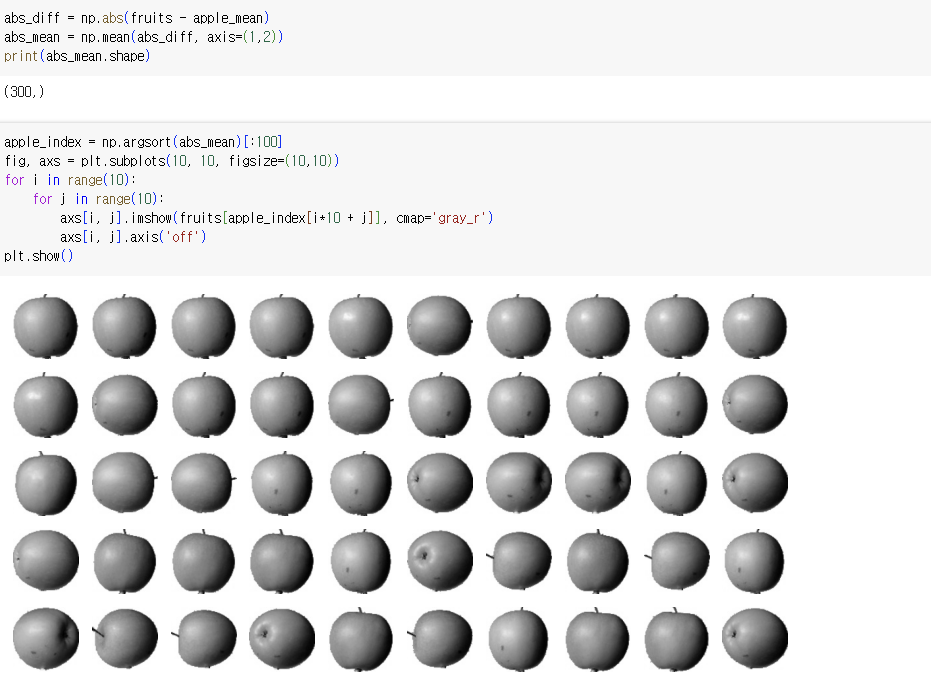
6.2 K-평균
1) k-평균 알고리즘 소개
1️⃣ 무작위로 k개의 클러스터 중심을 정한다.
2️⃣ 각 샘플에서 가장 가까운 클러스터 중심을 찾아 해당 클러스터의 샘플로 지정한다.
3️⃣ 클러스터에 속한 샘플의 평균값으로 클러스터 중심을 변경한다.
4️⃣ 클러스터 중심에 변화가 없을 때까지 2번으로 돌아가 반복한다.
2) KMeans 클래스
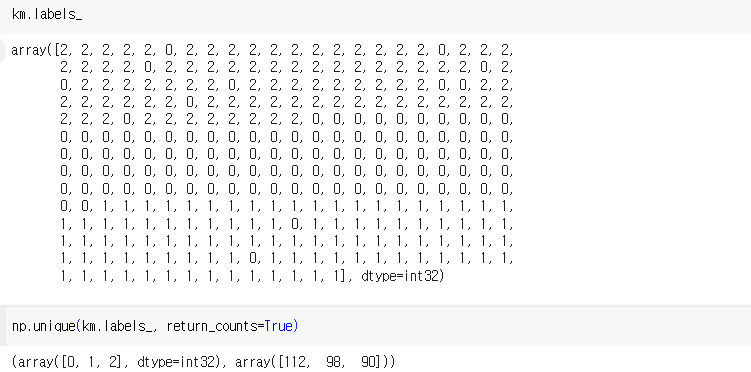


3) 클러스터 중심


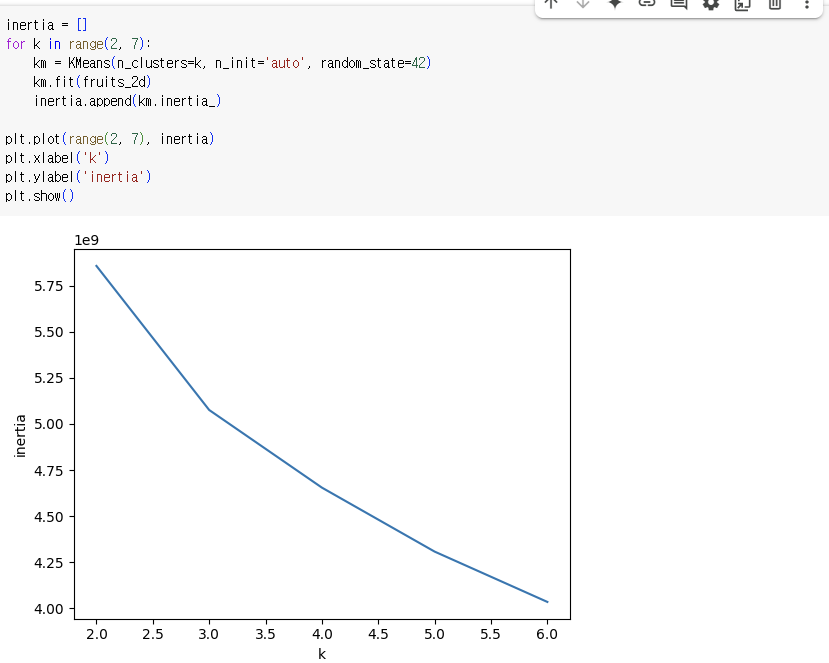
4) 최적의 k 찾기
- 엘보우 : 적절한 클러스터 개수를 찾기 위한 대표적인 방법
- 이니셔 : 클러스터 중심과 클러스터에 속한 샘플 사이의 거리의 제곱 합
6.3 주성분 분석
1) 차원과 차원 축소
- 차원 : 데이터가 가진 속성(특성)
- 차원 축소 : 데이터를 가장 잘 나타내는 일부 특성을 선택하여 데이터 크기를 줄이고 지도 학습 모델의 성능을 향상시킬 수 있는 방법
ex) 주성분 분석 (PCA)
2) 주성분 분석 소개
- 주성분은 원본 차원과 같고, 주성분으로 바꾼 데이터는 차원이 줄어든다.
- 주성분이 가장 분산이 큰 방향이기 때문에 주성분에 투영하여 바꾼 데이터는 원본이 가지고 있는 특성을 가장 잘 나타낼 것이다.
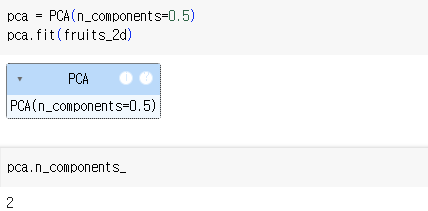
3) PCA 클래스

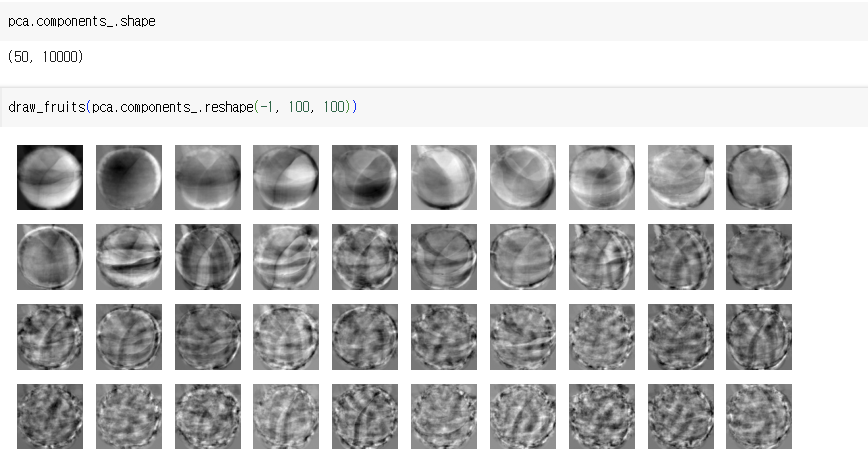



4) 설명된 분산
- 주성분이 원본 데이터의 분산을 얼마나 잘 나타내는지 기록한 값
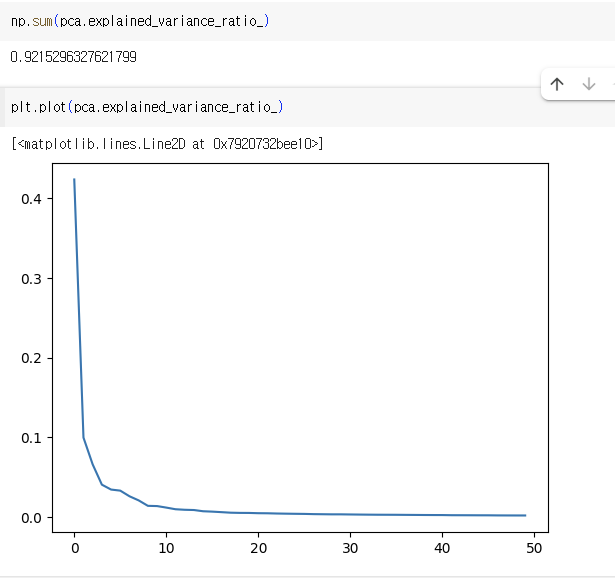
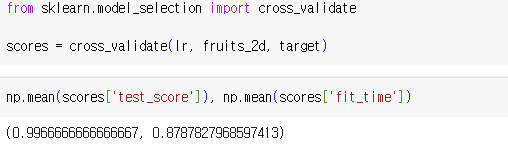
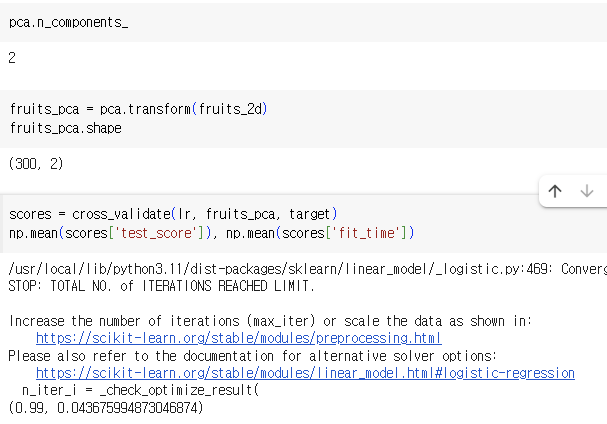
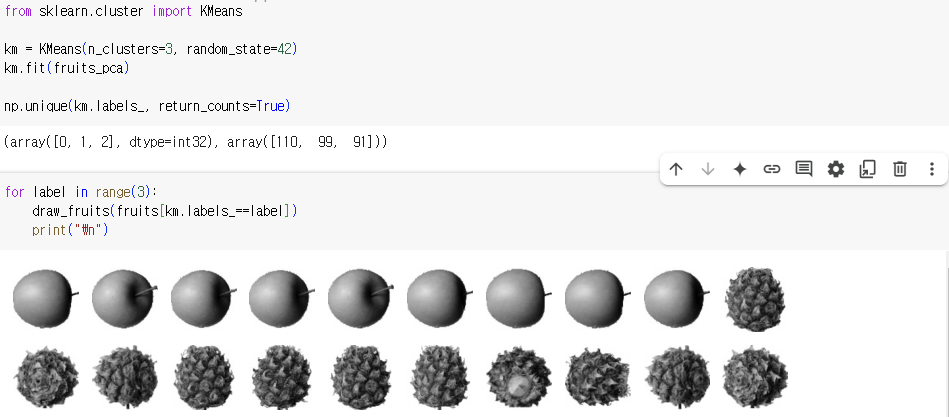
5) 다른 알고리즘과 함께 사용하기


💭 느낀 점
실제로 이미지를 출력해보는 과정이 많아서 이해가 잘 되었습니다.
'독학 > [책] 머신러닝+딥러닝' 카테고리의 다른 글
| [혼공학습단 13기 혼공머신🤖] 혼자 공부하는 머신러닝 + 딥러닝 week6 (0) | 2025.02.18 |
|---|---|
| [혼공학습단 13기 혼공머신🤖] 혼자 공부하는 머신러닝 + 딥러닝 week4 (0) | 2025.02.06 |
| [혼공학습단 13기 혼공머신🤖] 혼자 공부하는 머신러닝 + 딥러닝 week3 (0) | 2025.01.24 |
| [혼공학습단 13기 혼공머신🤖] 혼자 공부하는 머신러닝 + 딥러닝 week2 (0) | 2025.01.19 |
| [혼공학습단 13기 혼공머신🤖] 혼자 공부하는 머신러닝 + 딥러닝 week1 (0) | 2025.01.12 |