학회에서 데이터 스터디를 하고 여름방학부터 프로젝트를 하기로 했다. 스터디를 위해 첫 번째로 고른 강의는 다음과 같다.
[무료] 파이썬 무료 강의 (활용편5) - 데이터 분석 및 시각화 - 인프런 | 강의
파이썬을 활용하여 많은 양의 데이터를 분석하고, 분석한 데이터를 그래프 형태로 시각화하여 한 눈에 쉽게 파악할 수 있게 됩니다., - 강의 소개 | 인프런
www.inflearn.com
4월 10일부터 30일까지는 중간고사 기간으로 쉬어가고, 5월 중순까지 위 강의를 완강한 후 다음에 공부할 내용을 고를 예정이다. 섹션 0을 제외하고, 일주일에 6강씩 월요일부터 강의를 들은 후에 강의 내용을 블로그나 노션 등에 정리하고 링크를 일요일까지 공유한다. 이후 다음주 월요일에 구글 미트로 모르는 점을 공유하고 해결하는 등의 방식으로 1학기 스터디를 진행할 계획이다!
0. 환경설정
주피터 노트북를 사용하기 위해 아나콘다를 설치해야 했다. 나는 이전에 이미 다운로드했기 때문에 금방 넘어갔고, 주피터 사용법에 대한 부분부터 본격적으로 실습하면서 들었다.


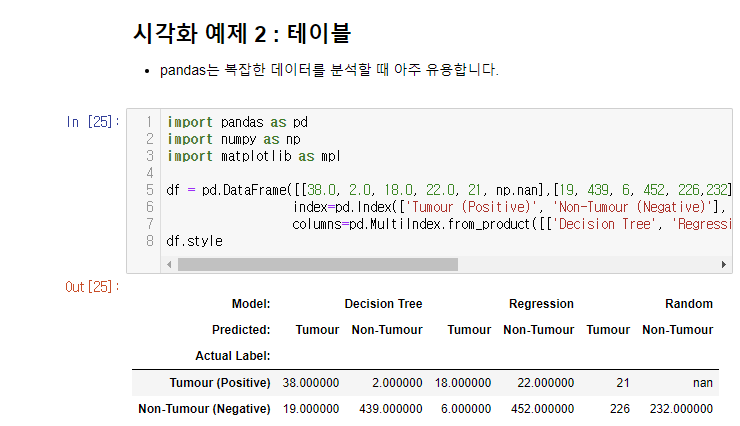
📌 Pandas (판다스) : 파이썬에서 사용하는 데이터 분석 라이브러리
- 데이터는 행과 열로, 2차원으로 구성되는데, 이를 간단하게 다룰 수 있다.
- 용량이 큰데이터도 안정적으로 처리할 수 있다.
- 파이썬에서 하는 대부분의 데이터 분석은 Pandas로 한다.
1. Series : 1차원 데이터(정수, 실수, 문자열 등)
1.1 Series 객체 생성
import pandas as pd
temp = pd.Series([-20, -10, 10 , 20])
print(temp)
1.2 Series 객체 생성 (Index 지정)
import pandas as pd
temp = pd.Series([-20, -10, 10, 20], index =['Jan', 'Feb', 'Mar', "Apr"])
print(temp)
2. DataFrame : 2차원 데이터 (Series들의 모음)
2.1 Data 준비 : 사전 (dict) 자료구조를 통해 생성한다.
data = {
'이름' : ['채치수', '정대만', '송태섭', '서태웅', '강백호', '변덕규', '황태산', '윤대협'],
'학교' : ['북산고', '북산고', '북산고', '북산고', '북산고', '능남고', '능남고', '능남고'],
'키' : [197, 184, 168, 187, 188, 202, 188, 190],
'국어' : [90, 40, 80, 40, 15, 80, 55, 100],
'영어' : [85, 35, 75, 60, 20, 100, 65, 85],
'수학' : [100, 50, 70, 70, 10, 95, 45, 90],
'과학' : [95, 55, 80, 75, 35, 85, 40, 95],
'사회' : [85, 25, 75, 80, 10, 80, 35, 95],
'SW특기' : ['Python', 'Java', 'Javascript', '', '', 'C', 'PYTHON', 'C#']
}
2.2 DataFrame 객체 생성
import pandas as pd
df = pd.DataFrame(data) #DataFrame을 df라 함.
2.3 데이터 접근

2.4 DataFrame 객체 생성 (Index 지정)
df = pd.DataFrame(data, index=['1번','2번','3번','4번','5번','6번','7번', '8번'])
df # index의 개수가 안 맞으면 에러
2.5 DataFrame 객체 생성 (Column 지정)
- data 중에서 원하는 column만 선택하거나, 순서 변경이 가능하다.

3. Index : 데이터에 접근할 수 있는 주소값
import pandas as pd
data = {
'이름' : ['채치수', '정대만', '송태섭', '서태웅', '강백호', '변덕규', '황태산', '윤대협'],
'학교' : ['북산고', '북산고', '북산고', '북산고', '북산고', '능남고', '능남고', '능남고'],
'키' : [197, 184, 168, 187, 188, 202, 188, 190],
'국어' : [90, 40, 80, 40, 15, 80, 55, 100],
'영어' : [85, 35, 75, 60, 20, 100, 65, 85],
'수학' : [100, 50, 70, 70, 10, 95, 45, 90],
'과학' : [95, 55, 80, 75, 35, 85, 40, 95],
'사회' : [85, 25, 75, 80, 10, 80, 35, 95],
'SW특기' : ['Python', 'Java', 'Javascript', '', '', 'C', 'PYTHON', 'C#']
}
df = pd.DataFrame(data, index=['1번','2번','3번','4번','5번','6번','7번', '8번'])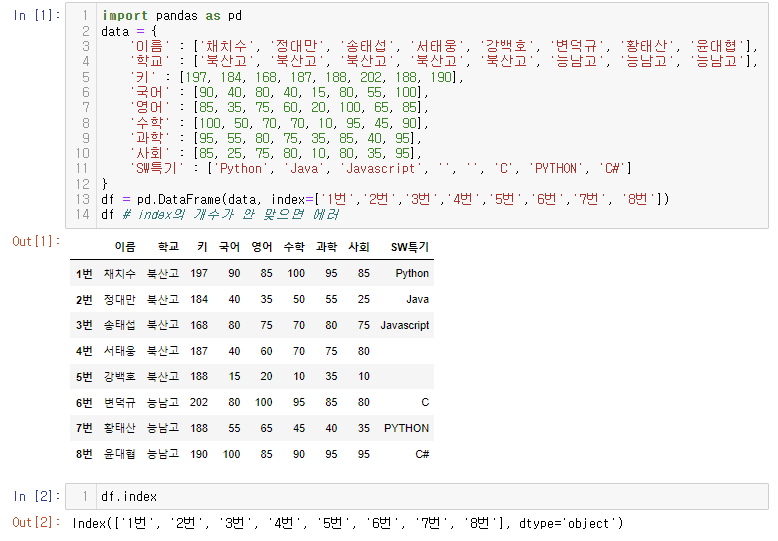
3.1 Index 이름 설정
df.index.name = '지정할 이름'
3.2 Index 초기화
df.reset_index()
df.reset_index(drop=True) # 원래 지정한 인덱스를 삭제함. 실제 데이터에는 반영되지 않음
df.reset_index(drop=True, inplace=True)
#실제 데이터에 바로 반영된다. (원본이 변하는 것이므로 유의해서 사용해야 함.)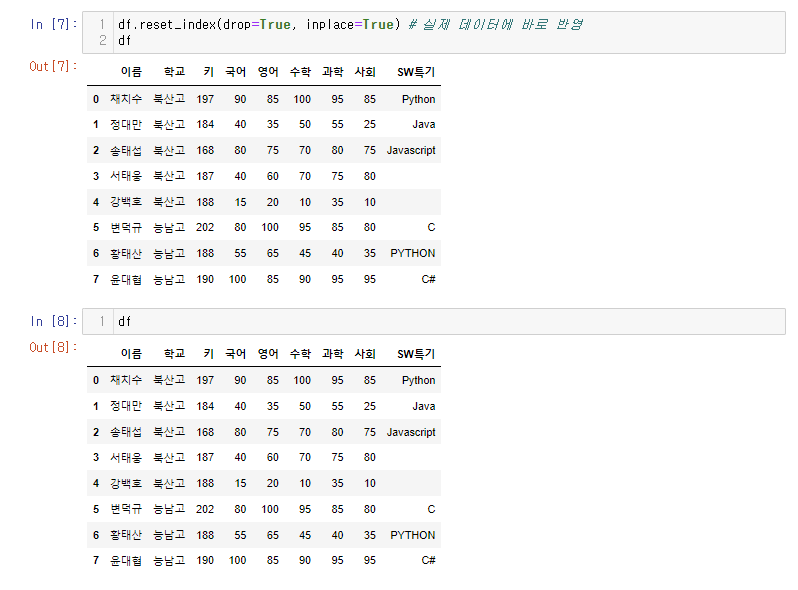
3.3 Index 설정 : 지정한 column으로 index를 설정한다.
df.set_index('index로 지정할 column의 이름') # 실제 데이터에 반영되지 않음

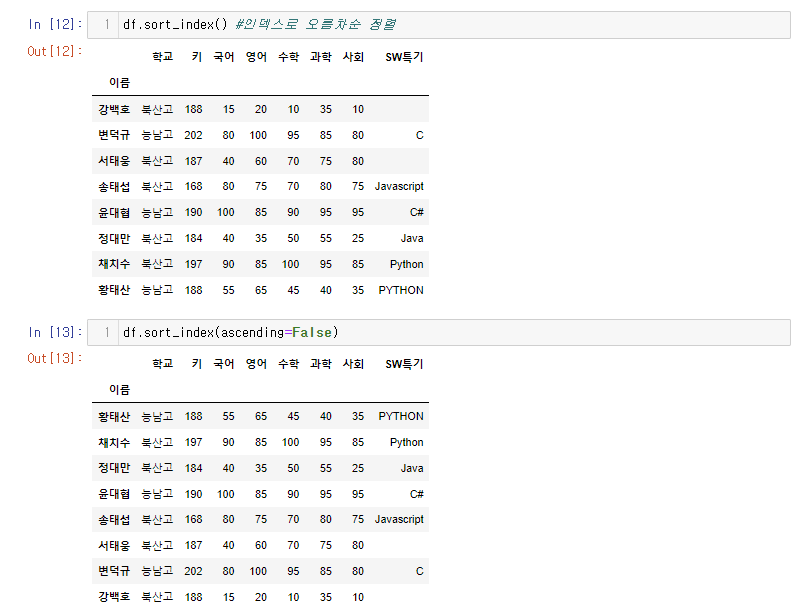
3.4 Index 정렬 : Index를 기준으로 오름차순 정렬, 내림차순 정렬이 가능하다.
4. 파일 저장 및 열기
- DataFrame 객체를 excel, csv, txt 등과 같은 형태의 파일로 저장 및 열기
4.1 저장하기
1) csv 파일로 저장
df.to_csv('score.csv', encoding='utf-8-sig')
# encoding을 작성하지 않으면, 엑셀에서 한글이 깨질 수 있으니 사용할 것
df.to_csv('score.csv', encoding='utf-8-sig', index=False)
# index를 빼고 저장2) 텍스트(.txt) 파일로 저장
df.to_csv('score.txt', sep='\t') # tab으로 구분된 텍스트 파일, TSV(Tab-separeted values)3) 엑셀 파일로 저장
df.to_excel('score.xlsx')4.2 열기
1) csv 파일 열기
df = pd.read_csv('score.csv')
df = pd.read_csv('score.csv', skiprows=1) #지정된 개수만큼의 row를 건너뛴다
df = pd.read_csv('score.csv', skiprows=[1,3,5]) #1, 3, 5 row는 제외 (row는 0부터 시작함)
df = pd.read_csv('score.csv', nrows=4) #지정된 개수만큼의 row만 가져온다
df = pd.read_csv('score.csv',skiprows=2, nrows=4) #처음 2개의 row 제외, 이후 4개의 row를 가져옴2) 텍스트(.txt) 파일 열기
df= pd.read_csv('score.txt', sep='\t') # sep를 기준으로 끊는다
df= pd.read_csv('score.txt', sep='\t', index_col = '지원번호') #지원번호를 인덱스로 함df = pd.read_csv('score.txt', sep='\t')
df.set_index('지원번호', inplace=True)
# df를 txt파일에서 읽어오고, 지원번호를 인덱스로 함. (df가 변함)3) 엑셀 파일 열기
df = pd.read_excel('score.xlsx')
df = pd.read_excel('score.xlsx', index_col = '지원번호')5. 데이터 확인

5.1 DataFrame 확인
df.describe()
# 계산 가능한 데이터에 대해 Column 별로 데이터의 개수, 평균, 표준편차, 최대/최솟값 등의 정보를 보여줌
df.info()
df.head() # 처음 다섯 개의 row를 가져온다.
df.head(n) #n은 정수, 처음 n개의 row를 가져온다.
df.tail() # 마지막 다섯 개의 row를 가져온다.
df.tail(n) #n은 정수, 마지막 n개의 row를 가져온다.
df.values
df.index
df.columns
df.shape #row, column의 개수를 보여준다.
5.2 Series 확인
df['column 이름'].descirbe() #해당 열에 속하는 값들의 정보 제공
df['column 이름'].min() #최솟값
df['column 이름'].max() #최댓값
df['column 이름'].mean() #평균
df['column 이름'].sum() #합계

df['column 이름'].nlargest(n) #해당 열에서 큰 데이터를 순서대로 n개
df['column 이름'].count() #NaN 제외 (유효한 데이터만 보여준다.)
df['column 이름'].unique() #중복을 제거하고 해당 열의 값을 보여준다.
df['column 이름'].nunique() #중복을 제거하고 남는 해당 열의 값의 개수
6. 데이터 선택 (기본)

6.1 Column 선택 (label)
6.2 Column 선택 (정수 index)

6.3 슬라이싱
df['가져올 column의 이름'][슬라이싱범위]
df[['가져올 column1의 이름', '가져올 column2의 이름']][슬라이싱범위]
이렇게 1주차 학습을 기록해봤습니다. 2주차 내용은 목요일이나 금요일 쯤 올릴 생각입니다.

'학회&동아리 > FORZA' 카테고리의 다른 글
| [FORZA STUDY] 나도코딩 - 데이터분석 및 시각화 week6 (2) | 2023.05.27 |
|---|---|
| [FORZA STUDY] 나도코딩 - 데이터분석 및 시각화 week5 (0) | 2023.05.21 |
| [FORZA STUDY] 나도코딩 - 데이터분석 및 시각화 week4 (0) | 2023.05.14 |
| [FORZA STUDY] 나도코딩 - 데이터분석 및 시각화 week3 (3) | 2023.05.08 |
| [FORZA STUDY] 나도코딩 - 데이터분석 및 시각화 week2 (2) | 2023.04.09 |