1. 데이터 수정
1.1 Column 수정
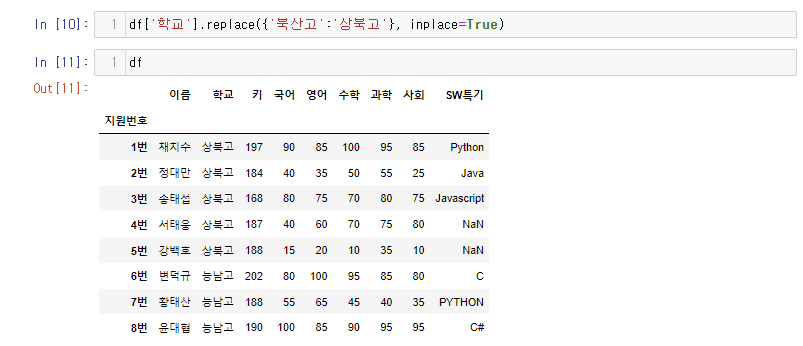
df['학교'].replace({'북산고':'상북고', '능남고':'무슨고'})
# 북산고를 전부 상북고로 변경, 능남고는 전부 무슨고로 변경
# 실제 데이터를 변경하기 위해서는 inplace=True 속성을 지정하면 됨.
📌 특정 열의 모든 값을 대/소문자로 변경하기
df['SW특기'] = df['SW특기'].str.upper() #대문자로 변경
df['SW특기'].str.lower() #소문자로 변경📌특정 열의 모든 값(문자열) 뒤에 특정 문자열 붙이기
df['학교'] = df['학교']+'등학교' # 학교 데이터 전체 각각에 문자열 붙이기
1.2 Column 추가
df['총합'] = df['국어']+df['영어']+df['수학']+df['과학']+df['사회'] # 새로운 열 추가
df['결과'] = 'Fail' # 결과 column을 추가하고,전체데이터는 Fail로 초기화
df.loc[df['총합']>400, '결과'] = 'Pass' #총합이 400보다 큰 데이터에 대해 결과를 Pass로 업데이트
1. 3 Column 삭제
df.drop(columns=['총합']) #지우고싶은 column 하나 삭제
df.drop(columns=['국어', '영어', '수학']) #국어, 영어, 수학 Column 삭제
# df.drop은 inplace=True 속성을 추가해야 실제데이터에 반영됨.1. 4 Row 삭제
df.drop(index='4번') #4번 학생 데이터 row 삭제
filt = df['수학'] < 80 #수학 점수가 80점 미만인 학생 필터링
df.drop(index=df[filt].index)

1. 5 Row 추가
df.loc['9번'] = ['이정환', '해남고등학교', 184, 90, 90, 90, 90, 90, 'Kotlin', 450, 'Pass'] #새로운 row 추가1. 6 Cell 수정
df.loc['4번', 'SW특기'] = 'Python' #4번 학생의 SW특기 데이터를 Python으로 변경
df.loc['5번', ['학교', 'SW특기']] = ['능남고등학교', 'C']
df #5번 학생의 학교는 능남고등학교로, SW특기는 C로 변경1. 7 Column 순서 변경
cols = list(df.columns)
df = df[[cols[-1]] + cols[0:-1]] # 맨 뒤의 결과를 맨 앞으로, 나머지를 합쳐서 순서 변경1. 8 Column 이름 변경
df.columns #이름 확인
df.columns = ['Result', 'Name', 'School'] #변경
2. 함수 적용
📌 에러 발생 -> 함수를 사용해 해결 가능
df['키'] = df['키']+ 'cm' #에러 발생 -> 키는 정수형, cm는 문자열이기 때문.2. 1 데이터에 함수 적용 (apply)
📌 키 뒤에 'cm' 붙이기
def add_cm(height):
return str(height)+'cm'
df['키'] = df['키'].apply(add_cm) #키 데이터에 대해서 add_cm을 호출한 데이터를 반영
df📌 첫 글자만 대문자로 하고 나머지는 소문자로 하는 함수 => str.capitalize() 내장함수와 같은 기능
def capitalize(lang):
if pd.notnull(lang): #NaN이 아닌지 확인
return lang.capitalize() #첫 글자는 대문자로, 나머지는 소문자로
return lang
df['SW특기'] = df['SW특기'].apply(capitalize)
df3. 그룹화
: 동일한 값을 가진 것들끼리 합쳐서 통계 또는 평균 등의 값을 계산하기 위해 사용
3. 1 groupby
df.groupby('학교')
df.groupby('학교').get_group('북산고')
3. 2 groupby 내 함수
df.groupby('학교').mean() #계산 가능한 데이터들의 평균값
📌 경고
https://github.com/pandas-dev/pandas/issues/46072
DEPR: DataFrameGroupBy numeric_only defaulting to True · Issue #46072 · pandas-dev/pandas
Context A summary of this behavior and the consensus thus far that DataFrameGroupBy will have numeric_only default to False in 2.0 can be found here: #42395 (comment). In #41475, the silent droppin...
github.com
위 링크를 자세히 읽어볼 필요가 있을 것 같다.
df.groupby('학교').size() #각 그룹의 크기 정보
df.groupby('학교').size()['능남고']
df.groupby('학교').size()['능남고'] # 학교로 그룹화환 뒤에 능남고에 해당하는 데이터의 수
df.groupby('학교')['키'].mean() #학교로 그룹화한 뒤에 키의 평균데이터
df.groupby('학교')[['국어', '영어', '수학']].mean()
#학교로 그룹화한 뒤에 국어, 영어, 수학 평균 데이터
df['학년'] = [3,3,2,1,1,3,2,2] # 학년 column 추가
df.groupby(['학교', '학년']).mean() #학교별,학년별 평균 데이터
df.groupby('학년').mean() # 학년별 평균 데이터

df.groupby('학년').mean().sort_values('키') # 오름차순 정렬
df.groupby('학년').mean().sort_values('키', ascending=False) # 내림차순 정렬
df.groupby(['학교', '학년']).sum()
df.groupby('학교')['SW특기'].count() # 학교로 그룹화한 뒤에 각 학교별 SW특기 데이터 수를 가져옴, NaN은 제외
df.groupby('학교')[['이름','SW특기']].count()
school = df.groupby('학교')
school['학년'].value_counts() #학교로 그룹화한 뒤, 학년별 학생 수를 가져옴
school['학년'].value_counts().loc['북산고'] # 학교로 그룹화한 뒤에 북산고에 대해 학년별 학생수를 가져옴
school['학년'].value_counts().loc['능남고'] # 학교로 그룹화한 뒤에 능남고에 대해 학년별 학생수를 가져옴
school['학년'].value_counts(normalize=True).loc['북산고'] #학생들의 수 데이터를 퍼센트로 비교하여 가져옴
Pandas 마무리 퀴즈



⭐ Matplotlib
다양한 형태의 그래프를 통해서 데이터 시각화를 할 수 있는 라이브러리
1. 그래프 기본
import matplotlib.pyplot as plt
matplotlib.rcParams['font.family'] = 'Malgun Gothic'
# 한글 서체 설정 Windows, Mac일 때는 AppleGothic, 사용하지 않으면 에러 발생
# matplotlib.rcParams['font.family'] = 'HYGungSo-Bold'# 궁서체
matplotlib.rcParams['font.size'] = 15 # 폰트 크기
matplotlib.rcParams['axes.unicode_minus'] = False # 한글 폰트 사용 시 마이너스 글자가 깨지는 것 방지
x = [1, 2, 3]
y = [2, 4, 8]1. 0 사용 가능한 폰트 확인
import matplotlib.font_manager as fm
fm.fontManager.ttflist # 사용 가능한 폰트 목록 확인 가능
[f.name for f in fm.fontManager.ttflist] # 폰트이름만 출력
1. 1 그래프 출력


1. 2 Title 설정
plt.plot(x, y)
plt.title('Line Graph')
plt.plot(x, y)
plt.title('꺾은선 그래프')plt.plot([-1, 0, 1], [-5, -1, 2]) # 직접 리스트를 이용해서 값을 넣는 것도 가능
2. 축
x = [1, 2, 3]
y = [2, 4, 8]
plt.plot(x, y)
plt.title('꺾은선 그래프', fontdict={'family':'HYGungSO-Bold', 'size':20}) #개별 폰트 설정
plt.plot(x, y)
plt.xlabel('X축') #x축에 이름 붙이기
plt.ylabel('Y축') #y축에 이름 붙이기
plt.plot(x, y)
plt.xlabel('X축', color='red') #이름의 색상 지정
plt.ylabel('Y축', color='#00aa00')
plt.plot(x, y)
plt.xlabel('X축', color='red', loc='right') #위치 지정. 값으로 left, right, center 가능
plt.ylabel('Y축', color='#00aa00', loc='top') #위치 지정. 값으로 top, center, bottom 가능
plt.plot(x, y)
plt.xticks([1, 2, 3]) # 그래프 축의 값
plt.yticks([3, 6, 9, 12]) # 그래프 축의 값
plt.show()
하루 지각했어요...^^

'학회&동아리 > FORZA' 카테고리의 다른 글
| [FORZA STUDY] 나도코딩 - 데이터분석 및 시각화 week6 (2) | 2023.05.27 |
|---|---|
| [FORZA STUDY] 나도코딩 - 데이터분석 및 시각화 week5 (0) | 2023.05.21 |
| [FORZA STUDY] 나도코딩 - 데이터분석 및 시각화 week4 (0) | 2023.05.14 |
| [FORZA STUDY] 나도코딩 - 데이터분석 및 시각화 week2 (2) | 2023.04.09 |
| [FORZA STUDY] 나도코딩 - 데이터분석 및 시각화 week1 (0) | 2023.04.02 |