📍기본 설정
import matplotlib.pyplot as plt
import matplotlib
matplotlib.rcParams['font.family'] = 'Malgun Gothic' # Windows, Mac일 때는 AppleGothic
#matplotlib.rcParams['font.family'] = 'HYGungSo-Bold'# 궁서체
matplotlib.rcParams['font.size'] = 15 # 폰트 크기
matplotlib.rcParams['axes.unicode_minus'] = False # 한글 폰트 사용 시 마이너스 글자가 깨지는 것 방지
import pandas as pd
df = pd.read_excel('../Pandas/score.xlsx')1. 산점도 그래프
1.1 산점도 그래프 그리기
plt.scatter(df['영어'], df['수학'])
plt.xlabel('영어 점수')
plt.ylabel('수학 점수')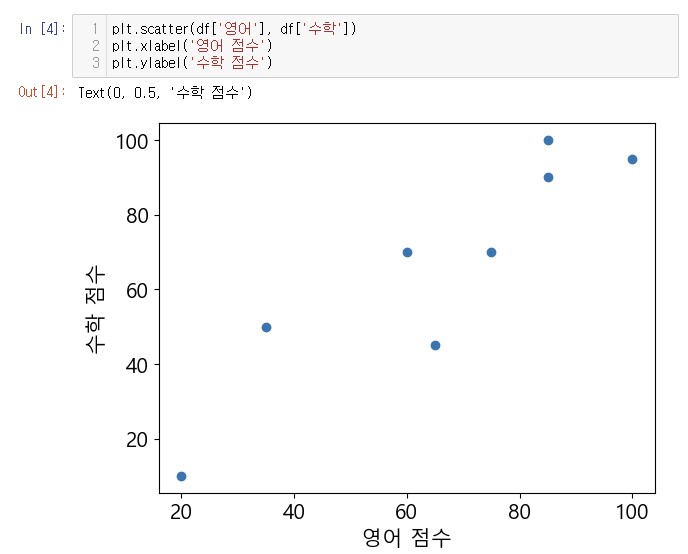
1.2 점에 변화 주기
1) 크기 조절
import numpy as np
sizes = np.random.rand(8) * 1000
plt.scatter(df['영어'], df['수학'], s = sizes) # 서로 다른 크기의 점
plt.xlabel('영어 점수')
plt.ylabel('수학 점수')
df['학년'] = [3, 3, 2, 1, 1, 3, 2, 2]
sizes = df['학년'] * 500 #1학년 : 500, 2학년 : 1000, 3학년 : 1500
plt.scatter(df['영어'], df['수학'], s = sizes) # 서로 다른 크기의 점
plt.xlabel('영어 점수')
plt.ylabel('수학 점수')
2) 색깔 지정
📌 아래 링크에서 세부 내용 확인 가능
https://matplotlib.org/stable/tutorials/colors/colormaps.html
Choosing Colormaps in Matplotlib — Matplotlib 3.7.1 documentation
Note Click here to download the full example code Choosing Colormaps in Matplotlib Matplotlib has a number of built-in colormaps accessible via matplotlib.colormaps. There are also external libraries that have many extra colormaps, which can be viewed in t
matplotlib.org
plt.scatter(df['영어'], df['수학'], s = sizes, c=df['학년'], cmap='viridis')
plt.xlabel('영어 점수')
plt.ylabel('수학 점수')

- 투명도 조절도 가능
plt.scatter(df['영어'], df['수학'], s = sizes, c=df['학년'], cmap='viridis', alpha=0.4)
plt.xlabel('영어 점수')
plt.ylabel('수학 점수')
3) colorbar
plt.figure(figsize=(10, 10))
plt.scatter(df['영어'], df['수학'], s = sizes, c=df['학년'], cmap='viridis', alpha=0.4)
plt.xlabel('영어 점수')
plt.ylabel('수학 점수')
plt.colorbar() #색상이 뜻하는 숫자를 확인 가능!
plt.figure(figsize=(10, 10))
plt.scatter(df['영어'], df['수학'], s = sizes, c=df['학년'], cmap='viridis', alpha=0.4)
plt.xlabel('영어 점수')
plt.ylabel('수학 점수')
plt.colorbar(ticks=[1, 2, 3], label='학년', shrink=0.5, orientation='horizontal')
2. 여러 그래프
fig, axs = plt.subplots(2, 3, figsize=(15, 10)) # 2*3에 해당하는 plots 생성
fig.suptitle('여러 그래프 넣기')
fig, axs = plt.subplots(2, 2, figsize=(15, 10))
fig.suptitle('여러 그래프 넣기')
#첫 번째 그래프
axs[0, 0].bar(df['이름'], df['국어'], label='국어점수') # 데이터 설정
axs[0, 0].set_title('첫 번째 그래프') # 제목
axs[0, 0].legend() # 범례
axs[0, 0].set(xlabel='이름', ylabel='점수') # x,y축 label
axs[0, 0].set_facecolor('lightyellow') # 전경색 지정
axs[0, 0].grid(linestyle='--', linewidth=0.5)
# 두 번째 그래프
axs[0, 1].plot(df['이름'], df['수학'], label='수학') # 데이터 설정
axs[0, 1].plot(df['이름'], df['영어'], label='영어')
axs[0, 1].legend() # 범례
# 세 번째 그래프
axs[1, 0].barh(df['이름'], df['키'], label='키') # 데이터 설정
#네 번째 그래프
axs[1, 1].plot(df['이름'], df['사회'], color='green', alpha=0.4)
퀴즈
import pandas as pd
import matplotlib.pyplot as plt
import matplotlib
matplotlib.rcParams['font.family'] = 'Malgun Gothic' # Windows
# matplotlib.rcParams['font.family'] = 'AppleGothic' # Mac
matplotlib.rcParams['font.size'] = 15
matplotlib.rcParams['axes.unicode_minus'] = False
data = {
'영화' : ['명량', '극한직업', '신과함께-죄와 벌', '국제시장', '괴물', '도둑들', '7번방의 선물', '암살'],
'개봉 연도' : [2014, 2019, 2017, 2014, 2006, 2012, 2013, 2015],
'관객 수' : [1761, 1626, 1441, 1426, 1301, 1298, 1281, 1270], # (단위 : 만 명)
'평점' : [8.88, 9.20, 8.73, 9.16, 8.62, 7.64, 8.83, 9.10]
}
df = pd.DataFrame(data)1) 영화 데이터를 활용해서 x축은 영화, y축은 평점인 막대그래프 그리기
plt.bar(df['영화'], df['평점'])
2) 1)의 막대그래프에 아래의 세부 사항을 적용하기
- 제목 : 국내 Top 8 영화 평점 정보
- x축 label : 영화 (90도 회전)
- y축 label : 평점
plt.bar(df['영화'], df['평점'])
plt.title('국내 Top 8 영화 평점 정보')
plt.xticks(rotation=90)
plt.xlabel('영화')
plt.ylabel('평점')
3) 개봉 연도별 평점 변화 추이를 꺾은선 그래프로 그리기
df_group = df.groupby('개봉 연도').mean()
plt.plot(df_group['평점'])
# 제시된 정답코드 : plt.plot(df_group.index, df_group['평점'])
4) 3)의 그래프에 아래의 세부사항 적용하기
- marker = 'o'
- x축 눈금 : 5년 단위 (2005, 2010, 2015, 2020)
- y축 눈금 : 최소 7, 최대 10
plt.plot(df_group['평점'], marker='o')
plt.xticks(range(2005, 2021, 5))
#plt.ticks([2005, 2010, 2015, 2020])
plt.ylim(7, 10)
5) 평점이 9점 이상인 영화의 비율을 확인할 수 있는 원 그래프를 제시된 세부사항을 적용해 그리기
- label : 9점 이상 / 9점 미만
- 퍼센트 : 소수점 첫째 자리까지 표시
- 범례 : 그래프 우측에 표시
'''
filt = df['평점']>=9.0
values = [len(df[flit]), len(df[~filt])]
'''
values = [df.loc[df['평점']>=9].shape[0], df.loc[df['평점']<9].shape[0]]
labels = ['9점 이상', '9점 미만']
plt.pie(values, labels=labels, autopct='%.1f%%')
plt.legend(loc=(1.0, 0.5))
인구 피라미드
- 2013년 4월의 연령별 인구현황 자료와 2023년4월의 연령별 인구현황 자료를 이용해 그래프를 그리고 비교
- 자료 : https://jumin.mois.go.kr/ageStatMonth.do
연령별 인구현황
연령별 인구현황 연령별 인구현황 해당 연도와 월의 행정기관별로 세대의 인구수를 확인 할 수 있는 연령별 인구현황 (월간) 행정기관코드 행정기관 2023년 04월 계 남 여 총 인구수 연령구간인구
jumin.mois.go.kr
1) 2013년 4월
(1) 남자 데이터 정의
import pandas as pd
file_name = '201304_201304_연령별인구현황_월간.xlsx'
df_m = pd.read_excel(file_name, skiprows=3, index_col='행정기관', usecols='B,E:Y')
df_m
- 위의 사진에서 숫자 내 , 제거하기
df_m.iloc[0] = df_m.iloc[0].str.replace(',', '').astype(int) # 반점 제거 후정수형으로 변환
df_m
(2) 여자 데이터 정의
df_w = pd.read_excel(file_name, skiprows=3, index_col='행정기관', usecols='B, AB:AV')
df_w.head(3) #나이에 대한 col이 두 개씩 있기때문에 뒤에 .1
df_w.columns = df_m.columns # 컬럼명 통일
df_w.columns
df_w.iloc[0] = df_w.iloc[0].str.replace(',', '').astype(int) # 반점 제거 후정수형으로 변환
df_w
(3) 그래프로 시각화
import matplotlib.pyplot as plt
import matplotlib
matplotlib.rcParams['font.family'] = 'Malgun Gothic' # Windows, Mac일 때는 AppleGothic
#matplotlib.rcParams['font.family'] = 'HYGungSo-Bold'# 궁서체
matplotlib.rcParams['font.size'] = 15 # 폰트 크기
matplotlib.rcParams['axes.unicode_minus'] = False # 한글 폰트 사용 시 마이너스 글자가 깨지는 것방지plt.figure(figsize=(10,7))
plt.barh(df_m.columns, -df_m.iloc[0] // 1000)
plt.barh(df_w.columns, df_w.iloc[0] // 1000)
plt.title('2023년 대한민국 인구 피라미드')
plt.savefig('2023_인구피라미드.png',dpi=100)
plt.show()
2) 2023년 4월
(1) 남자 데이터 정의
import pandas as pd
file_name = '202304_202304_연령별인구현황_월간.xlsx'
df_m = pd.read_excel(file_name, skiprows=3, index_col='행정기관', usecols='B,E:Y')
df_m
df_m.iloc[0] = df_m.iloc[0].str.replace(',', '').astype(int) # 반점 제거 후정수형으로 변환
df_m
(2) 여자 데이터 정의
df_w = pd.read_excel(file_name, skiprows=3, index_col='행정기관', usecols='B, AB:AV')
df_w.head(3) #나이에 대한 col이 두 개씩 있기때문에 뒤에 .1
df_w.columns = df_m.columns # 컬럼명 통일
df_w.columns
df_w.iloc[0] = df_w.iloc[0].str.replace(',', '').astype(int) # 반점 제거 후정수형으로 변환
df_w
(3) 그래프로 시각화
import matplotlib.pyplot as plt
import matplotlib
matplotlib.rcParams['font.family'] = 'Malgun Gothic' # Windows, Mac일 때는 AppleGothic
#matplotlib.rcParams['font.family'] = 'HYGungSo-Bold'# 궁서체
matplotlib.rcParams['font.size'] = 15 # 폰트 크기
matplotlib.rcParams['axes.unicode_minus'] = False # 한글 폰트 사용 시 마이너스 글자가 깨지는 것방지plt.figure(figsize=(10,7))
plt.barh(df_m.columns, -df_m.iloc[0] // 1000)
plt.barh(df_w.columns, df_w.iloc[0] // 1000)
plt.title('2023년 대한민국 인구 피라미드')
plt.savefig('2023_인구피라미드.png',dpi=100)
plt.show()
출생아 수 및 합계 출산율
- 2012년~2021년까지의 출생아 수와 합계 출산율을 하나의 그래프에 나타내기
- 자료 : https://www.index.go.kr/unity/potal/main/EachDtlPageDetail.do?idx_cd=1428
지표서비스 | e-나라지표
합계출산율 : 가임여성(15~49세) 1명 평생동안 낳을 것으로 예상되는 평균 출생아 수를 나타낸 지표로 연령별 출산율(ASFR)의 총합이며, 출산력 수준을 나타내는 대표적 지표 연령별 출산율(ASFR) : 1
www.index.go.kr
import pandas as pd
df = pd.read_excel('142801_20230527173206337_excel.xlsx', skiprows=2, nrows=2, index_col=0)
df
1) 인덱스 수정하기 : 인덱스 이름을 정확히 확인하고 사용하기 편한 형태로 변경하기

2) 전치 행렬을 원래의 행렬에 대체하기
df = df.T
3) 그래프로 시각화 : 조건들을 추가해가면서 보기 좋은 형태로 만들기
import matplotlib.pyplot as plt
import matplotlib
matplotlib.rcParams['font.family'] = 'Malgun Gothic' # Windows, Mac일 때는 AppleGothic
#matplotlib.rcParams['font.family'] = 'HYGungSo-Bold'# 궁서체
matplotlib.rcParams['font.size'] = 15 # 폰트 크기
matplotlib.rcParams['axes.unicode_minus'] = False # 한글 폰트 사용 시 마이너스 글자가 깨지는 것방지plt.plot(df.index, df['출생아 수'])
plt.plot(df.index, df['합계 출산율'])
fig, ax1 = plt.subplots(figsize=(10, 7)) #1,1
ax1.plot(df.index, df['출생아 수'], color='#ff812d')
ax2 = ax1.twinx() # x축을 공유하는 쌍둥이 axis
ax2.plot(df.index, df['합계 출산율'], color='#ffd100')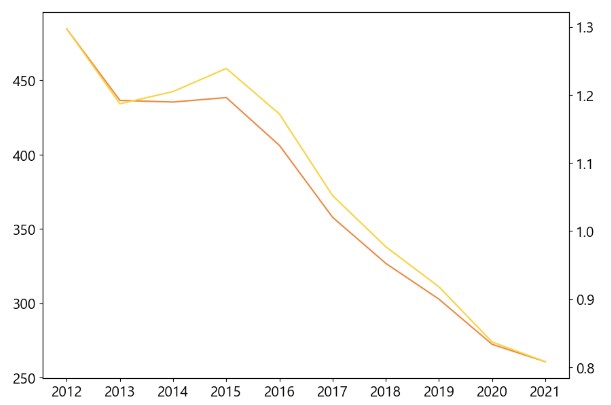
fig, ax1 = plt.subplots(figsize=(13, 5)) #1,1
ax1.set_ylabel ('출생아 수 (천 명)')
ax1.set_ylim(250, 700)
ax1.set_yticks([300, 400, 500,600])
ax1.bar(df.index, df['출생아 수'], color='#ff812d')
ax2 = ax1.twinx() # x축을 공유하는 쌍둥이 axis
ax2.set_ylabel('합계 출산율 (가임여성 1명당 명))')
ax2.set_ylim(0, 1.5)
ax2.set_yticks([0, 1])
ax2.plot(df.index, df['합계 출산율'], color='#ffd100')
fig, ax1 = plt.subplots(figsize=(13, 5)) #1,1
ax1.set_ylabel ('출생아 수 (천 명)')
ax1.set_ylim(250, 700)
ax1.set_yticks([300, 400, 500,600])
ax1.bar(df.index, df['출생아 수'], color='#ff812d')
for idx, val in enumerate(df['출생아 수']):
ax1.text(idx, val+12, val, ha='center')
ax2 = ax1.twinx() # x축을 공유하는 쌍둥이 axis
ax2.set_ylabel('합계 출산율 (가임여성 1명당 명))')
ax2.set_ylim(0, 1.5)
ax2.set_yticks([0, 1])
ax2.plot(df.index, df['합계 출산율'], color='#ffd100')
fig, ax1 = plt.subplots(figsize=(13, 5)) #1,1
ax1.set_ylabel ('출생아 수 (천 명)')
ax1.set_ylim(250, 700)
ax1.set_yticks([300, 400, 500,600])
ax1.bar(df.index, df['출생아 수'], color='#ff812d')
for idx, val in enumerate(df['출생아 수']):
ax1.text(idx, val+12, val, ha='center')
ax2 = ax1.twinx() # x축을 공유하는 쌍둥이 axis
ax2.set_ylabel('합계 출산율 (가임여성 1명당 명))')
ax2.set_ylim(0, 1.5)
ax2.set_yticks([0, 1])
ax2.plot(df.index, df['합계 출산율'], color='#ffd100', marker='o', ms=15, lw=5, mec='w', mew=3)
fig, ax1 = plt.subplots(figsize=(13, 5)) #1,1
ax1.set_ylabel ('출생아 수 (천 명)')
ax1.set_ylim(250, 700)
ax1.set_yticks([300, 400, 500,600])
ax1.bar(df.index, df['출생아 수'], color='#ff812d')
for idx, val in enumerate(df['출생아 수']):
ax1.text(idx, val+12, val, ha='center')
ax2 = ax1.twinx() # x축을 공유하는 쌍둥이 axis
ax2.set_ylabel('합계 출산율 (가임여성 1명당 명))')
ax2.set_ylim(0, 1.5)
ax2.set_yticks([0, 1])
ax2.plot(df.index, df['합계 출산율'], color='#ffd100', marker='o', ms=15, lw=5, mec='w', mew=3)
for idx, val in enumerate(df['합계 출산율']):
ax2.text(idx, val+ 0.08, val, ha='center')
fig, ax1 = plt.subplots(figsize=(13, 5)) #1,1
fig.suptitle('출생아 수 및 합계 출산율')
ax1.set_ylabel ('출생아 수 (천 명)')
ax1.set_ylim(250, 700)
ax1.set_yticks([300, 400, 500,600])
ax1.bar(df.index, df['출생아 수'], color='#ff812d')
for idx, val in enumerate(df['출생아 수']):
ax1.text(idx, val+12, val, ha='center')
ax2 = ax1.twinx() # x축을 공유하는 쌍둥이 axis
ax2.set_ylabel('합계 출산율 (가임여성 1명당 명))')
ax2.set_ylim(0, 1.5)
ax2.set_yticks([0, 1])
ax2.plot(df.index, df['합계 출산율'], color='#ffd100', marker='o', ms=15, lw=5, mec='w', mew=3)
for idx, val in enumerate(df['합계 출산율']):
ax2.text(idx, val+ 0.08, val, ha='center')

완강했습니다🥰 강의를 들으면서 pandas, matplotlib을 어떻게 사용하는지 배울 수 있었습니다.
'학회&동아리 > FORZA' 카테고리의 다른 글
| [FORZA STUDY] 스타트 코딩 - 이것이 진짜 크롤링이다 기본편 week2 (0) | 2023.06.30 |
|---|---|
| [FORZA STUDY] 스타트 코딩 - 이것이 진짜 크롤링이다 기본편 week1 (0) | 2023.06.21 |
| [FORZA STUDY] 나도코딩 - 데이터분석 및 시각화 week5 (0) | 2023.05.21 |
| [FORZA STUDY] 나도코딩 - 데이터분석 및 시각화 week4 (0) | 2023.05.14 |
| [FORZA STUDY] 나도코딩 - 데이터분석 및 시각화 week3 (3) | 2023.05.08 |