교재 : Do it SQL 입문 (이지스퍼블리싱, 강성욱)
3.1 SELECT문으로 데이터 검색하기
- SELECT 문
- 데이터베이스에서 데이터를 검색
- 시스템 성능에 많은 영향을 미치므로 주의해서 사용
1) 주석 작성 방법과 쿼리 실행 방법


- 한 줄 주석은 -- 으로, 여러 줄 주석은 /* 과 */ 사이에 내용을 입력한다.
- 여러 줄 쿼리를 작성한 채 실행하면 전체 쿼리가, 특정 쿼리를 드래그한 후 실행하면 특정 쿼리만 실행된다.
2) SELECT문으로 특정 열 검색하기
SELECT [열] FROM [테이블]- [열]에는 검색하려는 데이터의 열을 입력한다. 여러 열을 검색할 때는 , 로 구분해 연결한다. 전체 열을 검색하기 위해 *을 사용한다.


- 전체 열 검색은 자원을 많이 소비하므로 유의해야 한다.

3) SSMS에서 테이블의 열 정보 확인하기
- 아래와 같이 확장해 확인 가능

- 테이블 열 목록을 확인하는 시스템 함수 사용

- 쿼리 편집기에서 테이블 이름에 블록을 지정한 상태에서 alt + f1 실행

3.2 WHERE 문으로 조건에 맞는 데이터 검색하기
SELECT [열] FROM [테이블] WHERE [열] = [조건값]
1) WHERE문으로 특정 값 검색하기
- SQL Server가 제공하는 연산자 종류
| 연산자 | 설명 |
| < | 필터링 조건보다 작은 값 검색 |
| <= | 필터링 조건보다 작거나 같은 값 검색 |
| = | 필터링 조건과 같은 값 검색 |
| > | 필터링 조건보다 큰 값 검색 |
| >= | 필터링 조건보다 크거나 같은 값 검색 |
| <> != | 필터링 조건보다 같지 않은 값 검색 |
| !< | 필터링 조건보다 작지 않은 값 검색 |
| !> | 필터링 조건보다 크지 않은 값 검색 |
- 크기 비교 연산자는 숫자에만 사용 권장
2) WHERE문에서 비교 연산자 사용하기 - 예시


3) WHERE문에서 논리 연산자 사용하기
- 논리 연산자의 종류
| 연산자 | 설명 |
| ALL | 모든 비교 집합이 TRUE이면 TRUE |
| AND | 두 부울 표현식이 모두 TRUE이면 TRUE |
| ANY | 비교 집합 중 하나라도 TRUE이면 TRUE |
| BETWEEN | 피연산자가 범위 내에 있으면 TRUE |
| EXISTS | 하위 쿼리에 행이 포함되면 TRUE |
| IN | 피연산자가 리스트 중 하나라도 포함되면 TRUE |
| LIKE | 피연산자가 패턴과 일치하면 TRUE |
| NOT | 부울 연산자를 반대로 실행 |
| OR | 하나의 부울식이 TRUE이면 TRUE |
| SOME | 비교 집합 중 일부가 TRUE이면 TRUE |
- 사용 예시 : BETWEEN


- 사용 예시 : AND, OR


- 여러 데이터를 검색하기 위해 OR을 반복해서 사용 : 비효율적이므로 IN을 사용하면 된다.
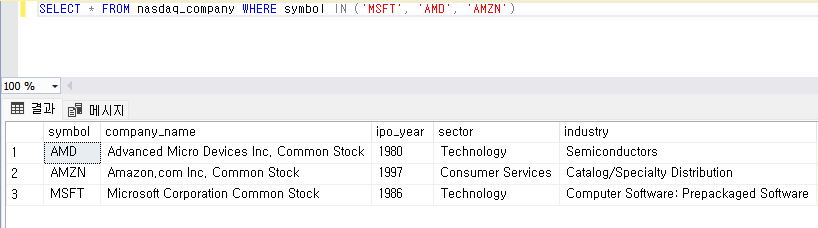
- 논리연산자의 우선순위를 고려해야 한다. 소괄호로 먼저 실행되어야 하는 커리에 우선순위를 부여할 수 있다.

- NULL데이터 검색
- NULL : 아예 정의되지 않은 값
- = 연산자를 이용하지 않고 IS NULL을 사용해 찾는다.

3.3 ORDER BY 문으로 데이터 정렬하기
- ORDER BY
SELECT [열] FROM [테이블] WHERE [열] = [조건값] ORDER BY [열] [ASC, DESC]
1) ORDER BY문으로 열 기준 정렬하기
- 열을 두 개 이상 기준으로 정렬할 때는 정렬 순서에 따라 쉼표를 사용해 열 이름을 나열한다.

2) ASC, DESC
- ASC : 오름차순 정렬로 기본 값이다.
- DESC : 내림차순 정렬
- 각 열 이름 뒤에 ASC, DESC를 붙여 쉼표로 연결하면 오름차순과 내림차순을 각 열에 적용한 다음 조합해 정렬할 수 있다.


3) TOP으로 상위 N개 데이터 검색하기

4) OFFSE ... FETCH NEXT로 지정한 개수만큼 행 건너뛰고 검색하기

- FETCH NEXT은 반드시 OFFSET과 함께 사용한다.

3.4 와일드 카드로 문자열 검색하기
- LIKE
SELECT [열] FROM [테이블] WHERE [열] LIKE [조건값]
1) LIKE와 %로 특정 문자열을 포함하는 문자열 검색하기
- % : 0개 이상의 문자열과 대치
| % | 내용 |
| A% | A로 시작하는 모든 문자열 |
| %A | A로 끝나는 모든 문자열 |
| %A% | A를 포함하는 모든 문자열 |




- 특수 문자를 포함한 문자열 검색하기
① 임시 테이블 생성

② ESCAPE와 #을 이용해 검색
- 쿼리 실행 시 #을 제거해 쿼리 명령 단계에서는 %#%%이 호출된다.
- 실제 실행 시에는 %%%로 해ㅓ괸다.
- ESCAPE에 사용되는 문자는 !, / 등 다른 문자도 가능하다.

2) _로 특정 문자열을 포함하는 특정 길이의 문자열 검색하기
- _의 사용방법 : _에 오는 글자는 무엇이든 상관없다.
| _ | 내용 |
| A_ | A로 시작하며 전체 글자는 2개인 문자열 |
| _A | A로 끝나며 전체 글자는 2개인 문자열 |
| _A_ | 세 글자 중 가운데 글자가 A인 문자열 |



3) _와 %을 조합해 문자열 검색하기

4) []로 문자나 문자 범위를 지정해 문자열 검색하기
- [] 사용방법
| 표현 | 내용 | |
| [A, B, C]% | [A-C]% | 첫 글자가 A, B, C 중 하나로 시작하는 모든 문자열 |
| %[A, B, C] | %[A-C] | 마지막 글자가 A, B, C 중 하나로 끝나는 모든 문자열 |

- 문자나 문자 범위를 제외한 문자열 검색하기 : ^

3.5 데이터 그룹화 다루기
- GROUP BY문과 HAVING문
SELECT [열] FROM [테이블] WHERE [열] = [조건값] GROUP BY [열] HAVING [열] = [조건문]
1) GROUP BY문으로 데이터 그룹화하기
- GROUP BY문에 사용한 열 이름이 SELECT문에 그대로 사용된다.
- 데이터를 그룹화할 때는 그룹 기준이 되는 열이 필요하므로 GROUP BY문에 사용한 열을 반드시 SELECT문에도 사용해야 한다.
- 중복 데이터를 제거한다.


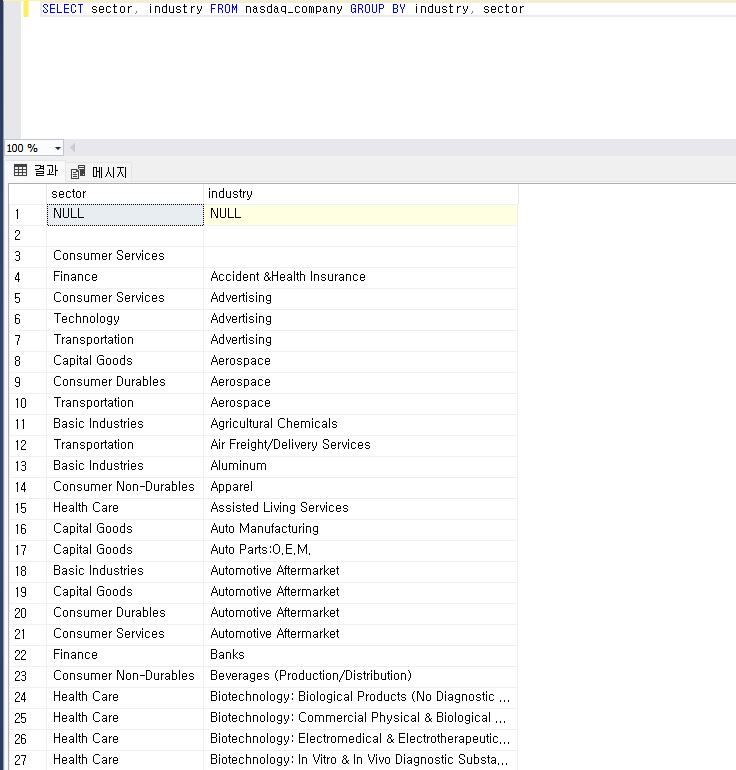
- 집계 함수 COUNT로 그룹화한 열의 데이터 개수 확인하기


2) HAVING 문으로 그룹화한 데이터 필터링하기
- SELECT나 GROUP BY문에 사용한 열에만 적용할 수 있다.


3) DISTINCT문으로 중복 데이터 제거하기
- DISTINCT
- 지정한 열의 중복 데이터를 제거한다.
- 집계나 계산이 필요할 때는 GROUP BY문을 사용해야 한다.
SELECT DISTINCT [열 이름] FROM [테이블 이름]

3.6 테이블 생성하고 데이터 조작하기
1) 데이터 조작 언어 (data manipulation langauge, DML)
- 테이블에 데이터를 검색(SELECT), 삽입(INSERT), 수정(UPDATE), 삭제(DELETE)하는 데 사용한다.
- 테이블을 대상으로 한다.
2) 데이터 정의언어 (data defination language, DDL)
- 테이블을 조작하는 언어
- 데이터베이스, 테이블, 뷰, 인덱스 등의 개체를 생성(CREATE), 삭제(DROP), 변경(ALTER)한다.
3) 데이터베이스 생성하고 삭제하기
- 생성
CREATE DATABASE [데이터베이스 이름]
- 삭제
DROP DATEBASE [데이터베이스 이름]
4) 테이블 생성하고 삭제
- 데이터베이스 선택하기
USE 데이터베이스 이름
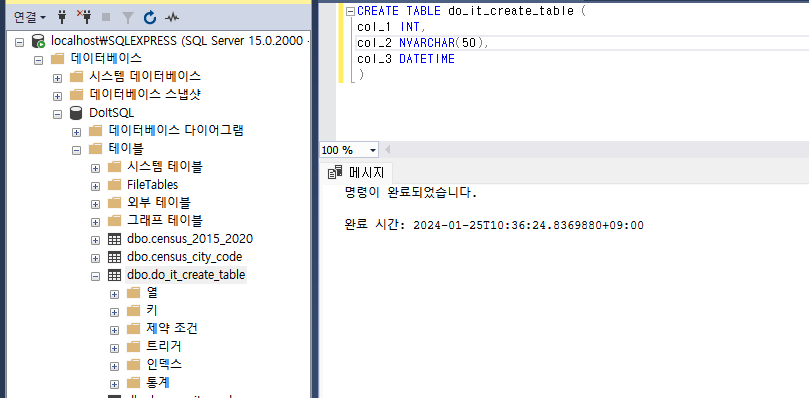
- CREATE 문으로 테이블 생성하기
CREATE TABLE 테이블이름 (
열1 자료형,
열2 자료형,
...
)
- DROP문으로 테이블 삭제
- 즉시 실행되니 유의해야 한다.
- 현재 삭제하려는 테이블이 다른 테이블과 종속 관계이면서 부모 테이블일 경우 삭제에 실패한다.

5) 테이블에 데이터 삽입, 수정, 삭제하기
- INSERT문으로 데이터 삽입하기
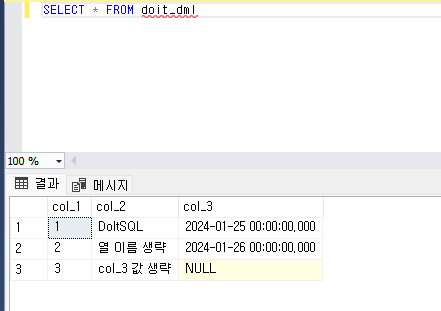
- 열 이름을 생략하고 테이블에 데이터를 삽입할 수 있다.
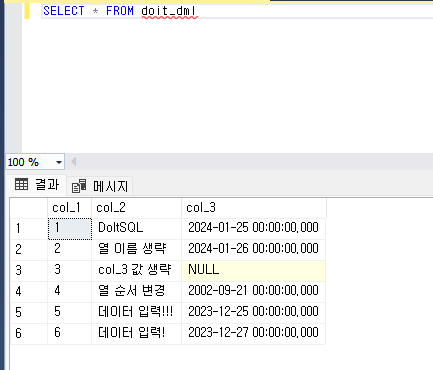
- 대상 열과 삽입할 데이터를 맞춰 소괄호에 나열하면 삽입하는 데이터의 순서를 바꿀 수 있다.
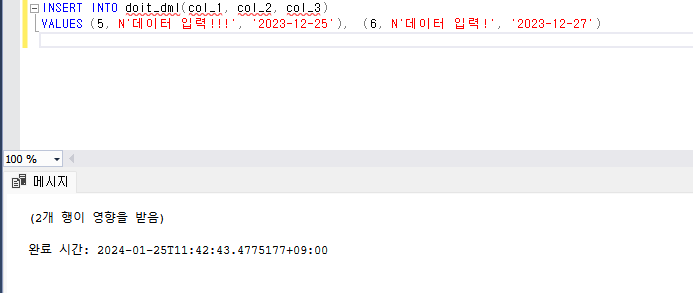
- 삽입할 값을 소괄호로 묶어 쉼표로 구분하면 여러 데이터를 한 번에 삽입할 수 있다.
INSERT INTO 테이블 [열1, 열2, ...] VALUES [값1, 값2, ...]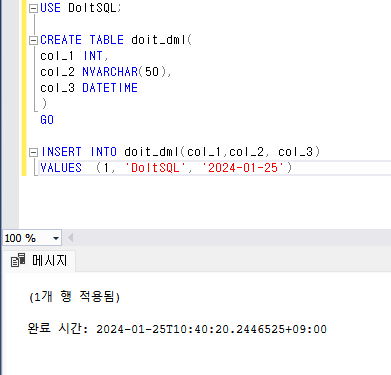






- NULL을 허용하지 않도록 테이블 생성하기
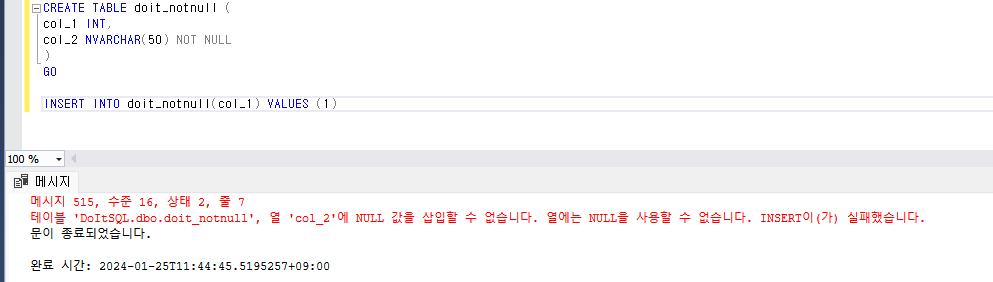
- UPDATE문으로 데이터 수정하기
- WHERE을 생략하면 테이블의 전체 데이터를 수정한다.
UPDATE [테이블 이름] SET [열1 = 값1, 열2 = 값2, ...]
WHERE [열] = [조건]

- DELETE문으로 데이터 삭제하기
DELETE [테이블 이름] WHERE [열] = [조건]

6) 외래키로 연결된 데이터 입력, 삭제하기
- 관계형 데이터베이스는 데이터의 무결성을 유지해야 하므로 부모 테이블에 없는 데이터를 자식 테이블이 가질 수 없다.
- 부모, 자식테이블 생성

- 데이터 입력 : 부모 테이블에 데이터를 입력하고 같은 값을 자식 테이블에 입력

- 데이터 삭제: 자식 테이블의 데이터를 먼저 삭제 후 부모 테이블의 데이터 삭제

- 테이블 삭제 : 자식 테이블, 부모 테이블 순서로 삭제해야 한다.

- 제약 조건 제거 : 자식 테이블의 데이터를 유지하면서 부모 테이블을 삭제하기 위함.
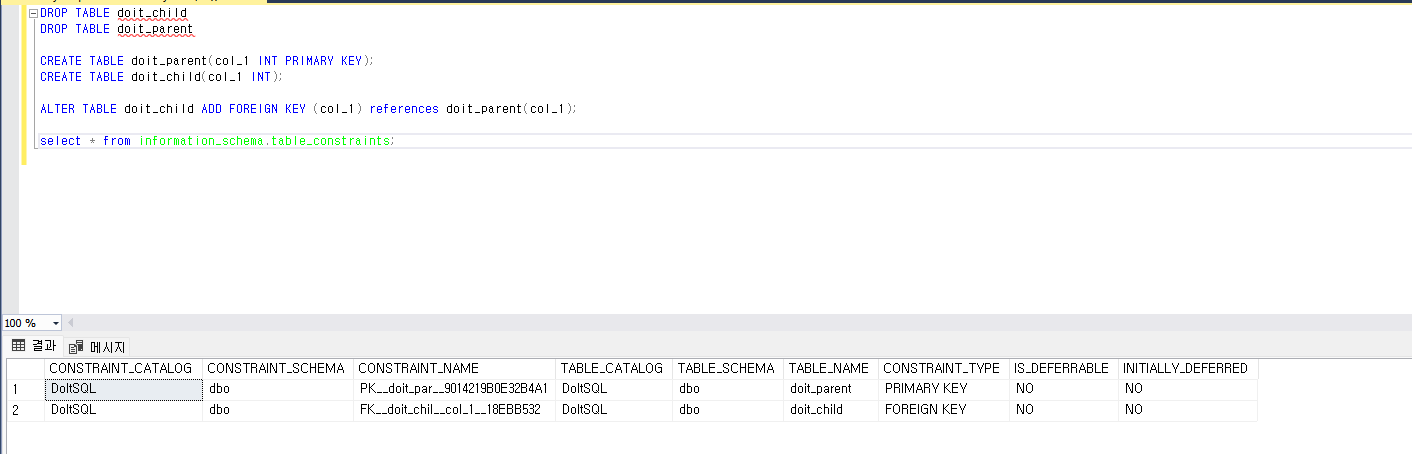

- 제약 조건과 제약 조건 이름 확인하기
- sp_help [테이블 이름] 실행
- 테이블 이름을 드래그한 상태에서 alt + f1
- select * from information_shema, table_constraints 실행

7) 다른 테이블에 검색 결과 입력하기
INSERT 대상 테이블
SELECT 열 FROM 기존 테이블
8) 새 테이블을 생성하며 검색 결과 입력하기
SELECT 열 INTO 새로운 테이블 FROM 기존 테이블
3.7 SQL Server에서 다루는 자료형 정리하기
1) 숫자형
| 자료형 | 데이터 크기 (byte) | 숫자 범위 | 설명 |
| bit | 1 | 0, 1, NULL | 불리언 형식 : 참(True, 1) 혹은 거짓(False, 0) |
| tinyint | 1 | 0 ~ 255 | 정수 데이터를 사용하는 정확한 숫자 자료형으로 숫자를 저장할 때 가장 많이 사용 |
| smallint | 2 | -32768 ~ 32767 | |
| int | 4 | -2^31 ~ 2^31-1 | |
| bigint | 8 | -2^63 ~ 2^63-1 | |
| decimal(p, s) | 5 ~ 17 | -10^38+1 ~ 10^38-1 | 전체 자릿수의 소수 자리수가 고정된 숫자로 최대 38자리 사용 |
| numberic(p, s) | 5 ~ 17 | -10^38+1 ~ 10^38-1 | |
| float (n) | 4 ~ 8 | -1.79E+308 ~ 1.79E+308 | |
| real | 4 | -3.40E+38 ~ 3.40E+38 | 부동 소수점 숫자 데이터에 사용하는 근사 숫자 자료형 |
| smallmoney | 4 | 약 -21억 ~ 21억 | 통화 단위에 주로 사용하며 1/10000까지 정확히 표현 가능 |
| money | 8 | -2^63 ~ 2^63-1 |
- 암시적 형 변환 : 실행 환경에서 자동으로 형 변환
- 명시적 형 변환
- CASTINT, CONVERT 등의 함수 이용
- 사용자가 직접 자료형 변경
2) 문자형
- 고정 길이 : 실제값을 입력하지 않아도 지정한 만큼의 저장 공간 사용
- 가변 길이 : 실제 입력한 크기만큼만 저장 공간 사용
| 자료형 | 데이터 크기(byte) | 설명 |
| char(n) | 0 ~ 8000 | 고정 길이 문자열 |
| nchar(n) | 0 ~ 8000 | 유니코드 고정 문자열, 4000자 입력 가능 |
| varchar(n|max) | 0 ~ 2^31-1 (2GB) | 가변 길이 문자열로 n만큼의 크기 지정 가능, max만큼 지정하면 2GB까지 가능 |
| nvarchar(n|max) | 0 ~ 2^31-1 | 유니코드 가변길이 문자열 |
| binary(n) | 0 ~ 8000 | 고정 길이의 이진데이터 값 |
| varbinary(n|max) | 0 ~ 2^31-1 | 가변 길이 이진 데이터 값, n을 사용하면 1~8000까지 크기를지정할 수 있고 max를 지정하면 2GB까지 크기 지정이 가능하다. 동영상 이미지 저장 등에 이용한다. |
- 함수
- LEN : 문자열 길이 확인
- DATALENGTH : 문자열 크기 확인
- 유니코드
- 한글이나 특수문자 저장
- 한 글자에 2 바이트
3) 날짜형과 시간형
| 자료형 | 데이터 크기(byte) | 정확도 | 설명 |
| time | 3 ~ 5 | 100나노초 | 00:00:00.0000000 ~ 23:59:59.9999999까지 저장 |
| date | 3 | 1일 | 0001-01-01 ~ 9999-12-31까지 저장되며 날짜만 저장 |
| smalldatetime | 4 | 1분 | 1900-01-01 00:00:00 ~ 2079-12-31 23:59:59까지 저장 |
| datetime | 8 | 0.00333초 | 1753-01-01 00:00:00.000 ~ 9999-12-31 23:59:59.997까지 저장 |
| datetime2 | 6 ~ 8 | 100나노초 | 0001-01-01 00:00:00.0000000 ~ 9999-12-31 23:59:59.9999999 까지 저장 (datetime의 확장) |
| datetimeoffset | 8 ~ 10 | 100나노초 | 0001-01-01 00:00:00.0000000 ~ 9999-12-31 23:59:59.9999999 까지 저장 + 타임존 시간을 함께 저장 |
'독학 > [책 + 인강] SQL' 카테고리의 다른 글
| [얄코 MySQL] 섹션 2 SELECT 더 깊이 파보기 (0) | 2024.04.05 |
|---|---|
| [얄코 MySQL] 섹션 1 SELECT 기초 - 원하는 정보 가져오기 (2) | 2024.03.25 |
| [SQL Server] Do it SQL 입문 5장 다양한 SQL 함수 사용하기 (0) | 2024.02.19 |
| [SQL Server] Do it SQL 입문 4장 테이블을 서로 조합하는 조인 알아보기 (0) | 2024.02.04 |
| [SQL Server] Do it SQL 입문 1장~2장 (2) | 2024.01.14 |